Конвейерные функциональные устройства и набор векторных команд - это две особенности таких машин. В отличие от традиционного подхода, векторные команды оперируют целыми массивами независимых данных, что позволяет эффективно загружать доступные конвейеры, т.е. команда вида A=B+C может означать сложение двух массивов, а не двух чисел.
Как правило, несколько специальных векторно-конвейерных процессоров (1-16) работают одновременно над общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько таких узлов могут быть объединены с помощью коммутатора (аналогично MPP).
Характерным представителем данного направления является семейство векторно-конвейерных компьютеров CRAY, куда входят, например, CRAY EL, CRAY J90, CRAY T90 (в марте 2000 года американская компания TERA перекупила подразделение CRAY у компании Silicon Graphics, Inc.).
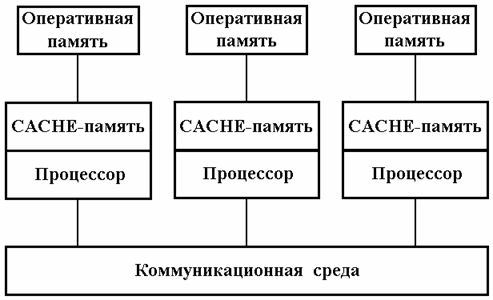
Массивно-параллельные компьютеры с распределенной памятью. Идея построения компьютеров этого класса тривиальна: возьмем серийные микропроцессоры, снабдим каждый своей локальной памятью, соединим посредством некоторой коммуникационной среды - вот и все (рис.2). Достоинств у такой архитектуры масса: если нужна высокая производительность, то можно добавить еще процессоров; если ограничены финансы или заранее известна требуемая вычислительная мощность, то легко подобрать оптимальную конфигурацию и т.п.
Однако есть и решающий "минус", сводящий многие "плюсы" на нет. Дело в том, что межпроцессорное взаимодействие в компьютерах этого класса идет намного медленнее, чем происходит локальная обработка данных самими процессорами. Именно поэтому написать эффективную программу для таких компьютеров очень сложно, а для некоторых алгоритмов – иногда просто невозможно.
К данному классу можно отнести компьютеры Intel Paragon, IBM SP1, Parsytec, в какой-то степени IBM SP2 и CRAY T3D/T3, хотя в этих компьютерах влияние указанного минуса значительно ослаблено. К этому же классу можно отнести и сети компьютеров, которые все чаще рассматривают как дешевую альтернативу крайне дорогим суперкомпьютерам.
Рис. 2. Системы с распределенной памятью
Вся оперативная память таких компьютеров разделяется несколькими одинаковыми процессорами (рис. 3). Это снимает проблемы предыдущего класса, но добавляет новые - число процессоров, имеющих доступ к общей памяти, по чисто техническим причинам нельзя сделать большим.
Наличие общей памяти значительно упрощает взаимодействие процессоров между собой, однако за этой кажущейся простотой скрываются большие проблемы, присущие системам этого типа. Помимо хорошо известной проблемы конфликтов при обращении к общей шине памяти возникла и новая проблема, связанная с иерархической структурой организации памяти современных компьютеров. Дело в том, что самым узким местом в современных компьютерах является оперативная память, скорость работы которой значительно отстала от скорости работы процессора. В настоящее время эта скорость примерно в 20 раз ниже требуемой для 100% согласованности со скоростью работы процессора, и разрыв все время увеличивается. Для того, чтобы сгладить разрыв в скорости работы процессора и основной памяти, каждый процессор снабжается скоростной буферной памятью (кэш-памятью), работающей со скоростью процессора. В связи с этим в многопроцессорных системах, построенных на базе таких микропроцессоров, нарушается принцип равноправного доступа к любой точке памяти. Для его сохранения приходится организовывать аппаратную поддержку когерентности кэш-памяти, что приводит к большим накладным расходам и сильно ограничивает возможности по наращиванию производительности таких систем путем простого увеличения числа процессоров.
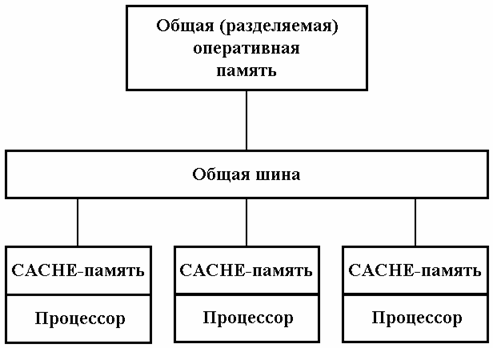
Рис. 3. Системы с общей памятью
В чистом виде SMP системы состоят, как правило, не более чем из 32 процессоров, а для дальнейшего наращивания используется NUMA-технология, которая в настоящее время позволяет создавать системы, включающие до 256 процессоров с общей производительностью порядка 150 млрд. операций в секунду. Системы этого типа производятся многими компьютерными фирмами как многопроцессорные серверы с числом процессоров от 2 до 64 и прочно удерживают лидерство в классе малых суперкомпьютеров с производительностью до 60 млрд. операций в секунду.
В данное направление входят многие современные многопроцессорные SMP-компьютеры или, например, отдельные узлы компьютеров HP Exemplar и Sun StarFire.
NUMA-архитектуры представляют собой нечто среднее между SMP и MPP. В таких системах память физически распределена, но логически общедоступна. Система состоит из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти в несколько раз быстрее, чем к удаленной.
Кластерные технологии стали логическим продолжением развития идей, заложенных в архитектуре MPP систем. Если процессорный модуль в MPP системе представляет собой законченную вычислительную систему, то следующий шаг напрашивался сам собой: почему бы в качестве таких вычислительных узлов не использовать обычные серийно выпускаемые компьютеры. Развитие коммуникационных технологий, а именно появление высокоскоростного сетевого оборудования и специального программного обеспечения такого, как MPI, реализующего механизм передачи сообщений над стандартными сетевыми протоколами, сделало кластерные технологии общедоступными. Сегодня не составляет большого труда создать небольшую кластерную систему, объединив вычислительные мощности компьютеров отдельной лаборатории или учебного класса.
Привлекательной чертой кластерных технологий является то, что они позволяют для достижения необходимой производительности объединять в единые вычислительные системы компьютеры самого разного типа, начиная от персональных компьютеров и заканчивая мощными суперкомпьютерами. С одной стороны, эти технологии используются как дешевая альтернатива суперкомпьютерам, в частности, одним из первых был реализован проект COCOA, в котором на базе 25 двухпроцессорных персональных компьютеров общей стоимостью порядка $100000 была создана система с производительностью, эквивалентной 48-процессорному Cray T3D стоимостью несколько миллионов долларов США. С другой стороны, эти технологии используются для преодоления ограничений, присущих SMP системам и векторно-конвейерным компьютерам.
Кластер - это связанный набор полноценных компьютеров, используемый в качестве единого ресурса. Существует два подхода при создании кластерных систем:
- объединение в единую систему полнофункциональных компьютеров, которые могут работать, в том числе, и как самостоятельные единицы, например, компьютеры учебного класса или рабочие станции лаборатории;
- целенаправленное создание мощного вычислительного ресурса, в котором роль вычислительных узлов играют промышленно выпускаемые компьютеры, и тогда нет необходимости снабжать такие компьютеры графическими картами, мониторами, дисковыми накопителями и другим периферийным оборудованием, что значительно удешевляет стоимость системы.
В последнем случае системные блоки компьютеров, как правило, компактно размещаются в специальных стойках, а для управления системой и для запуска задач выделяется один или несколько полнофункциональных компьютеров, которые называют хост-компьютерами. Преимущества кластерной системы перед набором независимых компьютеров очевидны. Во-первых, система пакетной обработки заданий позволяет послать задание на обработку кластеру в целом, а не какому-нибудь отдельному компьютеру, что позволяет обеспечить более равномерную загрузку компьютеров. Во-вторых, появляется возможность совместного использования вычислительных ресурсов нескольких компьютеров для решения одной задачи.
Для создания кластера используются компьютеры, которые могут представлять собой как простые однопроцессорные системы, так и обладать сложной архитектурой SMP и даже NUMA.
К настоящему времени разработано множество технологий соединения компьютеров в кластер. Наиболее простым вариантом является использование технологии Ethernet, однако за эту простоту приходится расплачиваться заведомо недостаточной скоростью обменов. Разработчики пакета подпрограмм ScaLAPACK [66], предназначенного для решения задач линейной алгебры на многопроцессорных системах, в которых велика доля коммуникационных операций, формулируют следующим образом требование к многопроцессорной системе: "Скорость межпроцессорных обменов между двумя узлами, измеренная в Mbyte/sec, должна быть не менее 1/10 пиковой производительности вычислительного узла, измеренной в MFLOPS". Коэффициент 1/10 получен из практического опыта, показывающего, что на большинстве приложений реальная производительность вычислительных систем составляет примерно 10% от пиковой производительности. Таким образом, если в качестве вычислительных узлов использовать компьютеры класса Pentium III 500 Mhz (пиковая производительность 500 MFLOP), то аппаратура Fast Ethernet (скорость передачи приблизительно 10 Mbyte/sec) обеспечивает только 1/5 от требуемой скорости. Это положение может существенно поправить переход на технологии Gigabit Ethernet.
Ряд фирм предлагают специализированные кластерные решения на основе более скоростных сетей таких, как SCI фирмы Scali Computer (~80 Mbyte/sec) и Mirynet (~40 Mbyte/sec). Активно включились в поддержку кластерных технологий и фирмы-производители высокопроизводительных рабочих станций (SUN, Compaq, Silicon Graphics).
По такому принципу построены CRAY SV1, HP Exemplar, Sun StarFire, NEC SX-5, последние модели IBM S2 и другие. Именно это направление является в настоящее время наиболее перспективным для конструирования компьютеров с рекордными показателями производительности.
Этот термин возник вместе с развитием высокоскоростной сетевой инфраструктуры в начале 90-х годов и относился к объединению нескольких разнородных вычислительных ресурсов в локальной сети организации для решения одной задачи. Основная цель построения мета-компьютера в то время заключалась в оптимальном распределении частей работы по вычислительным системам различной архитектуры и различной мощности. Например, предварительная обработка данных и генерация сеток для счета могли производиться на пользовательской рабочей станции, основное моделирование на векторно-конвейерном суперкомпьютере, решение больших систем линейных уравнений – на массивно-параллельной системе, а визуализация результатов – на специальной графической станции.
В дальнейшем исследования в области технологий мета-компьютинга были развиты в сторону однородного доступа к вычислительным ресурсам большого числа (вплоть до нескольких тысяч) компьютеров в локальной или глобальной сети [24]. Компонентами "мета-компьютера" могут быть как простейшие ПК, так и мощные массивно-параллельные системы. Что важно, мета-компьютер может не иметь постоянной конфигурации - отдельные компоненты могут включаться в его конфигурацию или отключаться от нее; при этом технологии мета-компьютинга обеспечивают непрерывное функционирование системы в целом. Современные исследовательские проекты в этой области направлены на обеспечение прозрачного доступа пользователей через Интернет к необходимым распределенным вычислительным ресурсам, а также прозрачного подключения простаивающих вычислительных систем к мета-компьютерам.
Очевидно, что наилучшим образом для решения на мета-компьютерах подходят задачи переборного и поискового типа, где вычислительные узлы практически не взаимодействуют друг с другом и основную часть работы производят в автономном режиме. Основная схема работы в этом случае примерно такая: специальный агент, расположенный на вычислительном узле (компьютере пользователя), определяет факт простоя этого компьютера, соединяется с управляющим узлом мета-компьютера и получает от него очередную порцию работы (область в пространстве перебора). По окончании счета по данной порции вычислительный узел передает обратно отчет о фактически проделанном переборе или сигнал о достижении цели поиска.