В рамках преподаваемых дисциплин специализаций на базе компьютерного класса кафедры Юнеско по НИТ был создан учебный кластер. Существующий вычислительный кластер обладает незначительной вычислительной мощностью, явно недостаточной для проведения ресурсоемких численных расчетов. В дальнейшем планируется создание первого в Кузбассе современного высокопроизводительного кластера с возможностью доступа к нему учреждений образования по региональной сети передачи данных (РСПД) КемГУ (в настоящий момент сеть связывает все факультеты КемГУ и филиалы КемГУ в городах Белово, Анжеро-Судженск, Новокузнецк; вузы г.Кемерово: Кемеровский Технологический институт пищевой промышленности, Кемеровскую государственную академию культуры и искусств, Кемеровский сельскохозяйственный институт), а также по Интернет.
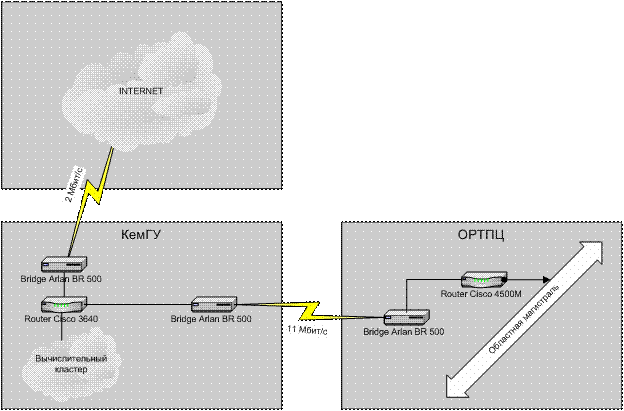
На рис. 6 приведена схема включения вычислительного ресурса в сеть КемГУ с возможностью его использования из Интернет и РСПД КемГУ.
Для организации параллельных вычислений на основе коммуникационной библиотеки MPI используется системный сервис Remote Shell, позволяющий запускать на удаленной машине приложения. Соответственно необходимо обеспечить защиту компьютеров кластера извне. Наиболее очевидный способ защиты – выделить один из компьютеров под шлюз, на котором производится авторизация внешних пользователей. После авторизации на шлюзе внешний пользователь получает доступ к кластеру (рис. 7).
Для удобной и наглядной работы исследователей на вычислительном кластере планируется создание серверного интерфейса на основе WWW-технологий, обеспечивающего удаленное администрирование кластера, возможность проведения удаленных вычислений на кластере, а также представление статистической информации о кластере (количество пользователей, загрузка вычислительной мощности кластера и т.д.).
Рис. 6. Схема доступа к кластеру из РСПД КемГУ и Интернет
Анализ существующих библиотек для проведения параллельных вычислений показал, что проще всего остановить свой выбор на операционной системе Redhat Linux и коммуникационной библиотеке mpich. Основным преимуществом MPI, по сравнению с другими коммуникационными библиотеками, является то, что интерфейс может работать как на сети ПК, так и на компьютерах с процессорами на общей памяти. Кроме того, mpich содержит огромный набор функций для передачи сообщений (порядка нескольких сотен) и поддерживается многими платформами. Дополнительное преимущество такого выбора обусловлено тем, что это программное обеспечение свободно распространяемое.
MPI (Message passing interface) - это стандарт на программный инструментарий для обеспечения связи между ветвями параллельного приложения. Минимально в состав MPI входят: библиотека программирования (заголовочные и библиотечные файлы для языков Си, Си++ и Фортран) и загрузчик приложений.
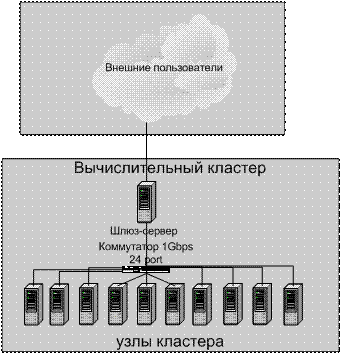
Рис. 7. Схема организации кластера
Для MPI принято писать программу, содержащую код всех ветвей сразу. MPI-загрузчиком запускается указываемое количество экземпляров программы. Каждый экземпляр определяет свой порядковый номер в запущенном коллективе и в зависимости от этого номера и размера коллектива выполняет ту или иную ветку алгоритма. Такая модель параллелизма называется Single program/Multiple data (SPMD) и является частным случаем модели Multiple instruction/Multiple data (MIMD). Каждая ветвь имеет пространство данных, полностью изолированное от других ветвей. Обмениваются данными ветви только в виде сообщений MPI.
Все ветви запускаются загрузчиком одновременно как процессы Unix. Количество ветвей фиксировано - в ходе работы порождение новых ветвей невозможно. Если MPI-приложение запускается в сети, запускаемый файл приложения должен быть построен на каждой машине. Загрузчик MPI приложений - утилита mpirun. Параллельное приложение будет образовано N задачами-копиями. В момент запуска все задачи одинаковы, но получают от MPI разные номера от 0 до N-1. В тексте параллельной программы эти номера используются для указания конкретному процессу, какую ветвь алгоритма он должен выполнять.
Специфика MPI - осуществляет связь между процессорами, передавая необходимые данные между ветвями параллельного алгоритма. Реализуется с помощью набора подпрограмм MPI.
Проблемы использования MPI: во-первых, перед запуском приложения необходимо копирование приложения на все компьютеры кластера; во-вторых, перед запуском приложения необходима информация о реально работающих компьютерах кластера для редактирования файла конфигурации кластера, который содержит имена машин; в-третьих, в MPI существующей реализации не поддерживается динамическое регулирование процессом, т.е. если один из узлов выходит из строя, то общий вычислительный процесс прекращается, и если добавляются новые узлы, то в запущенном ранее процессе они не участвуют.
Создание параллельной программы можно разбить на следующие этапы: последовательный алгоритм подвергается декомпозиции (распараллеливанию), т.е. разбивается на независимо работающие ветви; для взаимодействия в ветви вводятся две нематематические функции: прием и передача данных; распараллеленный алгоритм записывается в виде программы, в которой операции приема и передачи записываются в терминах MPI, тем самым обеспечивая связь между ветвями.
Тестирование производительности кластера можно разбить на несколько частей: тестирование коммуникаций, производительности отдельного узла кластера на наиболее популярном тесте и тестирование всего кластера при реализации параллельного алгоритма.
Для установки коммуникационной библиотеки MPICH необходимо выполнить следующие основные шаги:
1) настройка Linux;
2) копирование дистрибутива mpich;
3) конфигурирование mpich;
4) установка mpich;
5) настройка mpich;
6) первичная проверка успешной установки mpich;
7) донастройка Linux для более быстрого запуска параллельных приложений.
Ниже приводится подробное описание реализации каждого из пунктов.
Для возможности проведения отладки и профилирования параллельных приложений необходимо дополнительно установить Java-машину под операционную систему Linux до установки коммуникационной библиотеки MPICH.