Производительность кластера зависит от основных двух параметров: производительности отдельных узлов кластера и производительности коммуникационной среды.
Дистрибутив тестов для измерения производительности коммуникационной среды был взят с анонимного ftp - сервера НИВЦ МГУ:
ftp://parallel.ru/parallel/tests/bench-suite.tgz
В архиве с тестами прилагается подробное описание каждого теста (Андреев А.Н., Воеводин Вл.В. [37]) и параметров для его запуска, поэтому ниже дается лишь краткая выдержка для введения основных определений.
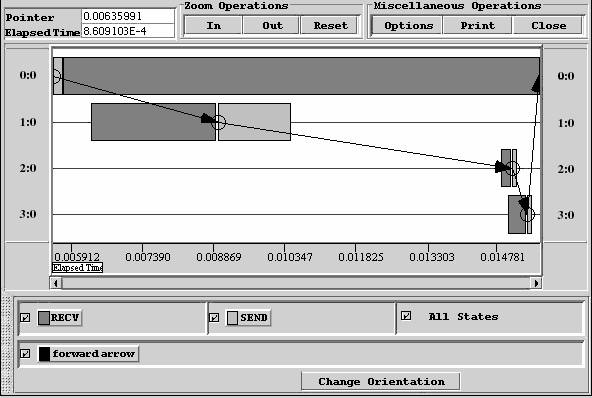
Рис. 9. Визуальный вид трассировки параллельной программы
Предположим, что на двух процессорах (узлах) вычислительной системы работают два процесса, между которыми с помощью сети (другой коммуникационной среды) пересылаются сообщения. В передаче информации, помимо аппаратных устройств, участвует и программное обеспечение, например, протокольный стэк (встроенный в ОС) и реализация интерфейса передачи сообщений MPI. Какими характеристиками определяется эффективность передачи информации между процессами параллельного приложения?
Основными характеристиками быстродействия сети являются латентность (latency) и пропускная способность (bandwidth) [37].
Определение 1. Под пропускной способностью R сети понимают количество информации, передаваемой между узлами сети в единицу времени (байт в секунду).
Очевидно, что реальная пропускная способность снижается программным обеспечением за счет передачи разного рода служебной информации.
Определение 2. Латентностью (задержкой) называется время, затрачиваемое программным обеспечением и устройствами сети на подготовку к передаче информации по данному каналу. Полная латентность складывается из программной и аппаратной составляющих.
Различают следующие виды пропускной способности сети:
1) пропускная способность однонаправленных пересылок ("точка-точка", uni-directional bandwidth), равная максимальной скорости, с которой процесс на одном узле может передавать данные другому процессу на другом узле;
2) пропускная способность двунаправленных пересылок (bi-directional bandwidth), равная максимальной скорости, с которой два процесса могут одновременно обмениваться данными по сети.
В чем измеряются эти величины?
Значения пропускной способности выражают в мегабайтах в секунду (MB/sec), значения латентности - в микросекундах (usec = 10-6 sec).
Из чего складывается время на пересылку сообщения?
Время T(L), необходимое на передачу сообщения длины L байт, можно определить следующим образом: T(L)=s+L/R, где s – латентность, а R – пропускная способность сети.
Для приложений с тонкой параллельной структурой (fine-grained parallelism), какими, как правило, являются вычислительные программы, крайне важны малые величины латентности; тогда как для приложений, использующих большие объемы пересылок (а это, как правило, коммерческие приложения БД), более важно максимальное увеличение пропускной способности.
Для измерения пропускной способности "точка-точка" используется следующая методика. Процесс с номером 0 посылает процессу с номером 1 сообщение длины L байт. Процесс 1, приняв сообщение от процесса 0, посылает ему ответное сообщение той же длины. Используются блокирующие (blocking) вызовы MPI (MPI_Send, MPI_Recv). Эти действия повторяются N раз с целью минимизировать погрешность за счет усреднения. Процесс 0 измеряет время T, затраченное на все эти обмены. Пропускная способность R определяется по формуле:
R=2NL/T.
Пропускная способность двунаправленных обменов определяется по той же формуле. В этом случае используются неблокирующие (non-blocking) вызовы MPI (MPI_Isend, MPI_Irecv). При этом производится измерение времени, затраченного процессом 0 на передачу сообщения процессу 1 и прием ответа от него, при условии, что процессы начинают передачу информации одновременно после точки синхронизации.
Латентность измеряется как время, необходимое на передачу сигнала или сообщения нулевой длины. При этом, для снижения влияния погрешности и низкого разрешения системного таймера, важно повторить операцию посылки сигнала и получения ответа большое число раз.
Пропускная способность кластера при однонаправленных обменах для различных размеров пересылаемого пакета приведена в таблице 6, при двунаправленных обменах – в таблице 7.
Таблица 6
Размер данных, байт |
1024 |
16384 |
32768 |
65536 |
Скорость пересылки, Mb/sec |
4,4 |
8,5 |
8,7 |
8,7 |
Таблица 7
Размер данных, Байт |
1024 |
16384 |
32768 |
65536 |
Скорость пересылки, Mb/sec |
6,7 |
9,2 |
9,6 |
9,9 |
Латентность в среднем составила 100*10-6 sec.
Результаты тестирования сети полностью соответствуют прогнозам: скорость передачи данных растет с увеличением размера пакета и на пакетах длиной 64 Kb достигает 10 Mb/sec.
Изначально кластера создавались для решения научно-технических задач, в которых существенно используется арифметика с плавающей точкой. Для оценки их производительности применяется единица измерения MFLOP, равная миллиону элементарных операций над числами с плавающей точкой, выполненных в секунду. Для кластеров вводится понятие суммарной или пиковой производительности, равной количеству процессоров умноженному на производительность одного из процессоров. Эта характеристика на реальных приложениях недостижима, т.к. ее можно получить лишь в одном вырожденном случае, когда ветви приложения, запущенные на разных процессорах, никак друг с другом не взаимодействуют.
Производительность кластера Юнеско КемГУ определялась с использованием алгоритма из пакета LINPACK (http://www.netlib.org/linpack) для решения систем линейных алгебраических уравнений методом LU разложения, который представляет собой набор последовательных фортрановских подпрограмм для матричных вычислений [27, 14, 53]. Суммарная производительность кластера составила 162 MFLOP (27 MFLOP на каждом узле) для чисел с плавающей точкой одинарной точности и 102 MFLOP (17 MFLOP на каждом узле) для двойной точности при размерности обращаемой матрицы 1000х1000 в обоих случаях. Зависимость производительности компьютера от размерности обращаемой матрицы приведена на рис. 10.
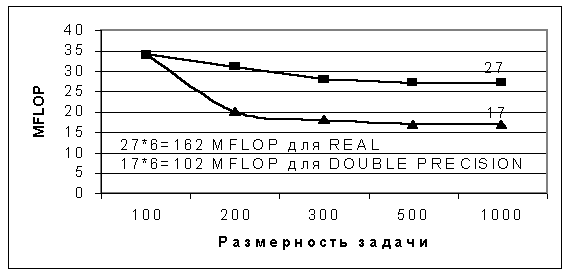
Рис. 10. Результаты теста LINPACK при его реализации на одном компьютере
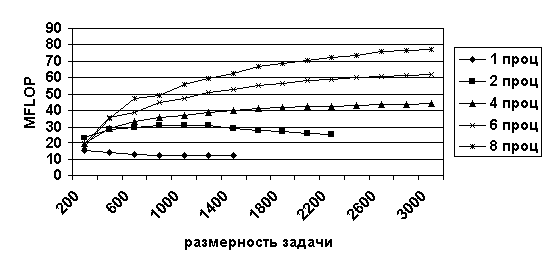
Рис. 11. Результаты теста SCALAPACK при его реализации на различном числе компьютеров
Для сравнения на кластере была установлена библиотека SCALAPACK (http://www.netlib.org/scalapack) для матричных вычислений, являющаяся параллельным аналогом библиотеки LINPACK. Для тестирования кластера был выбран тот же самый алгоритм. Число выполненных операций с плавающей точкой оценивается по формуле 2n3/3 + 2n2 (здесь n - размерность матрицы). При решении системы уравнений с матрицей 3000x3000 на 8 процессорах кластера была получена производительность 78 MFLOP.
Результаты замеров производительности (MFLOP) в зависимости от размерности обращаемой матрицы и количества узлов кластера (1, 2, 4, 6, 8) приведены на рис. 11.
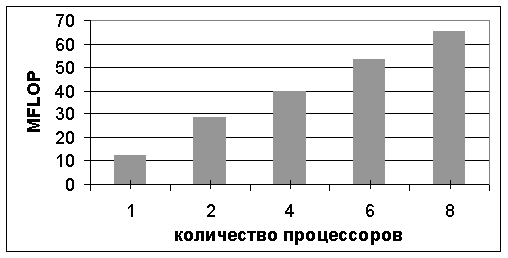
Рис. 12. Масштабируемость кластера
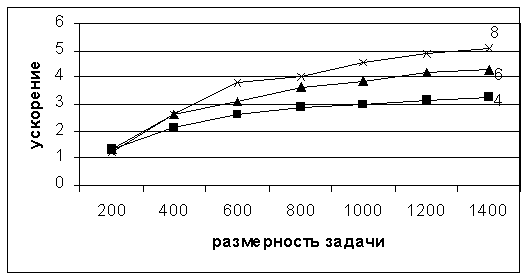
Рис. 13. Ускорение реализации параллельного алгоритма на кластере
На рис. 12 показана масштабируемость кластера при обращении матрицы размерности 1500х1500 при количестве узлов, составляющих кластер – 1, 2, 4, 6, 8. Данная характеристика демонстрирует эффективность добавления новых узлов для реализации параллельного алгоритма. Анализируя рис. 12, можно утверждать, что с ростом числа процессоров производительность увеличивается и при некотором числе процессоров достигнет своего максимума, после чего добавление новых узлов повлечет ухудшение производительности. Этот эффект можно объяснить исходя из того, что с ростом числа процессоров для реализации одного и того же алгоритма растет доля межпроцессорного обмена, при этом доля вычислений для каждого процессора в отдельности уменьшается.
На рис. 13, 14 приведены ускорение и эффективность алгоритма решения СЛАУ при его реализации на 4, 6 и 8 процессорах, соответственно.
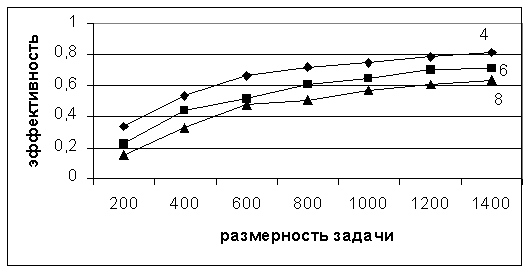
Рис. 14. Эффективность реализации параллельного алгоритма на кластере
Для справки ниже приводятся вычислительные характеристики суперкомпьютеров из списка TOP500, особое внимание уделено российским вычислительным ресурсам и ресурсам, принадлежащим вузам сибирского региона.
Данные о высокопроизводительных компьютерах представляют большой интерес для производителей, пользователей и потенциальных пользователей подобных систем. Такие люди хотят знать не только количество работающих систем, но и расположение различных суперкомпьютеров, а также решаемые с их помощью задачи. Подобная статистика способствует взаимодействию между различными исследовательскими лабораториями, обмену данными и ПО и делает рынок высокопроизводительных компьютеров более понятным.
В 1993 году была создана организация TOP500.ORG, целью которой является сбор и публикация информации о суперкомпьютерах. Дважды в год с помощью экспертов, ученых и производителей эта организация создает список пятисот самых производительных на данный момент суперкомпьютеров. Ознакомиться с этим списком можно на официальном сайте организации: www.top500.org.
Самый «слабый» суперкомпьютер, занимающий 500-ю строчку, создан фирмой IBM в 2000 году. Его производительность составляет «всего» 136.00 GFlops. А самый мощный вычислительный комплекс в истории человечества создала японская фирма NEC. Ее компьютер, который называется Earth-Simulator, выполняет 35860 млрд. операций с плавающей точкой в секунду. Его теоретическая пиковая производительность составляет 40960 GFlops. Earth-Simulator почти в пять раз быстрее ASCI White фирмы IBM, который занимает вторую позицию, и производительнее всех компьютеров из первой десятки вместе взятых!
Большую часть списка составляют суперкомпьютеры MPP архитектуры (224 системы или 44,8% от общего числа). 187 суперкомпьютеров (37,4% списка) построены на смешении нескольких архитектур. Среди 500 суперкомпьютеров 80 штук (16%) являются кластерными установками. Причем в первой десятке их три (это кластеры AlphaServer фирмы Hewlett-Packard). А самый производительный в мире кластер (3-е место в Top500) состоит из 3016 процессоров. Архитектура SMP представлена лишь девятью суперкомпьютерами.
Многие российские научные и образовательные учреждения уже являются обладателями высокопроизводительных вычислительных систем. Подробную информацию о российских ВПВ ресурсах можно найти на сайте www.parallel.ru, здесь же приведем лишь некоторые примеры.
Большое количество суперкомпьютеров расположены в московских организациях. Впервые в список Top500 вошел российский суперкомпьютер МВС1000М Межведомственного суперкомпьютерного центра (http://www.jscc.ru). МВС1000М состоит из 768 процессоров, имеет производительность 564 Gflops (пиковая - 1024 Gflops) и занимает 64-ю позицию.
Российско-Индийский Центр компьютерных исследований (http://www.riccr.com) оснащен суперкомпьютером PARAM 10000. Он состоит из 16 процессоров Ultra Sparc II и имеет пиковую производительность 16 GFlops.
В Нижегородском государственном университете им. Лобачевского (www.unn.ac.ru) с помощью корпорации Intel был установлен гетерогенный кластер из 26 узлов, содержащий 44 процессора.
Во многих крупных городах Сибири работают кластерные системы. Например, в Томском государственном университете (www.tsu.ru) кластер состоит из 9 двухпроцессорных компьютеров на базе процессоров Intel Pentium III 650 МГц под управлением ОС Free BSD.
В Сибирском суперкомпьютерном центре (www2.sscc.ru), созданном на базе Института вычислительной математики и математической геофизики (ИВМиВГ СО РАН, г. Новосибирск) установлен суперкомпьютер МВС1000/М производительностью 1,55 GFlops. Конфигурация этого вычислительного комплекса аналогична конфигурации МВС-1000М московского Межведомственного суперкомпьютерного центра, с тем лишь отличием, что в Новосибирске он состоит из пяти вычислительных узлов против 768-ми в Москве. Тем не менее единая архитектура и ПО гарантируют, что программы, отлаженные на Новосибирском МВС1000/М, будут работать и на Московском. Но основными вычислительными мощностями ССКЦ являются два SMP комплекса RM600-E30 производительностью 5,5 GFlops каждый.
Тестирование учебного кластера показало привлекательность использования такого подхода для создания вычислительного ресурса. Существующий учебный кластер КемГУ мало пригоден для проведения реальных научных расчетов: малая вычислительная производительность, возможность проведения расчетов только лишь в ночное время (в дневное время компьютерный класс занят под учебный процесс), не настроены сервисы для внешнего использования. Таким образом, актуальным стоит вопрос создания в КемГУ многопроцессорного вычислительного комплекса, построенного на основе кластеризации, при этом существующие кластерные системы можно использовать для обучения параллельному программированию.