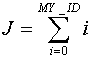 .
.Любая прикладная MPI-программа должна начинаться с вызова функции инициализации MPI (функция MPI_Init). В результате выполнения этой функции создается группа процессов, в которую помещаются все процессы приложения, и создается область связи, описываемая предопределенным коммуникатором MPI_COMM_WORLD. Эта область связи объединяет все процессы приложения. Процессы в группе упорядочены и пронумерованы от 0 до groupsize-1, где groupsize равно числу процессов в группе. Кроме этого, создается предопределенный коммуникатор MPI_COMM_SELF, описывающий свою область связи для каждого отдельного процесса.
Синтаксис функции инициализации MPI_Init значительно отличается в языках C и FORTRAN:
FORTRAN:
INTEGER IERR
MPI_INIT(IERR)
C:
int MPI_Init(int *argc, char ***argv)
В программах на C каждому процессу при инициализации передаются аргументы функции main, полученные из командной строки. В программах на языке FORTRAN параметр IERR является выходным и возвращает код ошибки.
Функция завершения MPI программ MPI_Finalize.
FORTRAN:
INTEGER IERR
MPI_FINALIZE(IERR)
C:
int MPI_Finalize(void)
Функция закрывает все MPI-процессы и ликвидирует все области связи.
Функция определения числа процессов в области связи MPI_Comm_size.
FORTRAN:
INTEGER COMM, SIZE, IERR
MPI_COMM_SIZE(COMM, SIZE, IERR)
C:
int MPI_Comm_size(MPI_Comm comm, int *size)
Входные параметры:
|
comm |
- |
коммуникатор. |
Выходные параметры:
|
size |
- |
число процессов в области связи коммуникатора comm. |
Функция возвращает количество процессов в области связи коммуникатора comm.
До создания явным образом групп и связанных с ними коммуникаторов единственно возможными значениями параметра COMM являются MPI_COMM_WORLD и MPI_COMM_SELF, которые создаются автоматически при инициализации MPI. Подпрограмма является локальной.
Функция определения номера процесса MPI_Comm_rank.
FORTRAN:
INTEGER COMM, RANK, IERR
MPI_COMM_RANK(COMM, RANK, IERR)
C:
int MPI_Comm_rank(MPI_Comm comm, int *rank)
Входные параметры:
|
comm |
- |
коммуникатор. |
Выходные параметры:
|
rank |
- |
номер процесса, вызвавшего функцию. |
Функция возвращает номер процесса, вызвавшего эту функцию. Номера процессов лежат в диапазоне 0..size-1 (значение size может быть определено с помощью предыдущей функции). Подпрограмма является локальной.
1 PROGRAM EXAMPLE
2 INCLUDE 'mpif.h'
3 INTEGER my_id, np, comm, ierr
4 CALL MPI_Init(ierr)
5 comm=MPI_COMM_WORLD
6 CALL MPI_Comm_Size(comm, np, ierr)
7 CALL MPI_Comm_Rank(comm, my_id, ierr)
8 Write(*,*) 'Hello, ',my_id,' processor
9 * of ',np, ' processors'
10 CALL MPI_Finalize(ierr)
11 STOP
12 END
Рис. 15. Пример использования обрамляющих функций MPI
1 PROGRAM EXAMPLE
2 INCLUDE 'mpif.h'
3 INTEGER my_id, np, comm,ierr
4 CALL MPI_Init(ierr)
5 comm=MPI_COMM_WORLD
6 CALL MPI_Comm_Size(comm, np, ierr)
7 CALL MPI_Comm_Rank(comm, my_id, ierr)
8 Write(*,*) 'Hello, ',my_id,' processor
9 * of ',np, 'processors'
10 j=0
11 do i=0,my_id
12 j=j+i
13 end do
14 Write(*,*) my_id,': j=',j
15 CALL MPI_Finalize(ierr)
16 STOP
17 END
Рис. 16. Пример использования идентификатора процесса
1 program EXAMPLE
2 include 'mpif.h'
3 integer my_id, np, tag, count, ierr, summa, namelen
4 integer status(MPI_STATUS_SIZE)
5 character p_name
6 call MPI_Init(ierr)
7 call MPI_Comm_rank(MPI_COMM_WORLD, my_id, ierr)
8 call MPI_Comm_size(MPI_COMM_WORLD, np, ierr)
9 call MPI_Get_processor_name(p_name, namelen)
10 print *, p_name , mpi_comm_world
11 call MPI_Finalize(ierr)
12 stop
13 end
Рис. 17. Пример для вывода имен машин кластера
На рис. 15 приведен пример программы, использующей обрамляющие функции MPI: строка 4 – инициализация библиотеки MPI, строка 6 – получение числа процессоров, на которых запущено данное параллельное приложение, 7 – получение идентификатора процесса, индивидуального для каждого процессора, 9 – завершение всех MPI-процессов.
При создании программ
требуется, чтобы каждый процессор выполнял свою ветвь параллельного алгоритма,
механизм реализации заключается в использовании ранга: в условии, в цикле и т.д.
На рис. 16 приведен пример, демонстрирующий использование идентификатора
процесса при вычислении суммы ряда, при этом на каждом узле кластера будет
получена следующая сумма:
.
На рис. 17 приведен пример программы, позволяющий получить имена машин, составляющих кластер.
В минимальный набор необходимых для написания параллельных приложений функций следует включить также две функции передачи и приема сообщений.
Функция передачи сообщения MPI_Send.
FORTRAN:
INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERR
<type> BUF(*)
MPI_SEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERR)
C:
int MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest,int tag, MPI_Comm comm)
Входные параметры:
|
buf |
- |
адрес начала расположения пересылаемых данных; |
|
count |
- |
число пересылаемых элементов; |
|
datatype |
- |
тип посылаемых элементов; |
|
dest |
- |
номер процесса-получателя в группе, связанной с коммуникатором comm; |
|
tag |
- |
идентификатор сообщения (аналог типа сообщения функций nread и nwrite PSE nCUBE2); |
|
comm |
- |
коммуникатор области связи. |
Функция выполняет посылку count элементов типа datatype сообщения с идентификатором tag процессу dest в области связи коммуникатора comm. Переменная buf - это, как правило, массив или скалярная переменная. В последнем случае значение count = 1.
Функция приема сообщения MPI_Recv.
FORTRAN:
<type> BUF(*)
INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM
INTEGER STATUS(MPI_STATUS_SIZE), IERR
MPI_RECV(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS, IERR)
C:
int MPI_Recv(void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)
Входные параметры:
|
count |
- |
максимальное число принимаемых элементов; |
|
datatype |
- |
тип элементов принимаемого сообщения; |
|
source |
- |
номер процесса-отправителя; |
|
tag |
- |
идентификатор сообщения; |
|
comm |
- |
коммуникатор области связи. |
Выходные параметры:
|
buf |
- |
адрес начала расположения принимаемого сообщения; |
|
status |
- |
атрибуты принятого сообщения. |
Функция выполняет прием count элементов типа datatype сообщения с идентификатором tag от процесса source в области связи коммуникатора comm.
Ниже приведен ряд примеров для организации передачи данных с использованием пары коммуникационных функций: MPI_Send,MPI_Recv.
На рис. 18 приведен пример передачи переменной buf от нулевого процессора всем процессорам, в том числе и самому себе.
1 PROGRAM EXAMPLE
2 INCLUDE 'mpif.h'
3 INTEGER my_id, np, comm,ierr, status
4 REAL*8 Buf
5 CALL MPI_Init(ierr)
6 comm=MPI_COMM_WORLD
7 CALL MPI_Comm_Size(comm, np, ierr)
8 CALL MPI_Comm_Rank(comm, my_id, ierr)
9 IF (my_id.EQ.0) Then
10 Buf=1
11 DO I=0,NP-1
12 CALL MPI_Send(Buf,1,MPI_REAL8,I,1,comm,ierr)
13 END DO
14 End IF
15 CALL MPI_Recv(Buf,1, MPI_REAL8,0,1,comm,status,ierr)
16 Write(*,*) my_id,': Buf=',Buf
17 CALL MPI_Finalize(ierr)
18 STOP
19 END
Рис. 18. Пример пересылки переменной от нулевого процессора всем остальным процессорам
1 PROGRAM EXAMPLE
2 INCLUDE 'mpif.h'
3 INTEGER my_id, np, comm,ierr, status
4 INTEGER Buf(8)
5 CALL MPI_Init(ierr)
6 comm=MPI_COMM_WORLD
7 CALL MPI_Comm_Size(comm, np, ierr)
8 CALL MPI_Comm_Rank(comm, my_id, ierr)
9 CALL MPI_Send(MY_ID,1,MPI_INTEGER,0,1,comm,ierr)
10 IF (my_id.EQ.0) Then
11 do I=1,NP
12 CALL MPI_Recv(Buf(I),1, MPI_INTEGER,
13 * i-1,1,comm,status,ierr)
14 Write(*,*) my_id,': Buf=',Buf(i)
15 END DO
16 End IF
17 CALL MPI_Finalize(ierr)
18 STOP
19 END
Рис. 19. Пример пересылки данных со всех процессоров на нулевой процессор
На рис. 19 приведен пример передачи переменной my_id со всех процессоров на нулевой процессор и формирование во время передачи данных на нулевом процессоре массива из присылаемых переменных.
В примере на рис. 20 переменные next и prev служат для задания топологии “кольцо”, передача данных осуществляется с использованием заданной топологии. В MPI существуют специальные функции для задания топологий. Далее при изучении функций задания топологий мы реализуем топологию кольцо, но уже с использованием функций MPI. На рис. 21 показано схематическое представление пересылок. Визуализация трассы исполнения параллельной программы приведена на рис. 22. Анализируя рисунок, можно сделать следующие пояснения: нулевой процессор после инициализации посылает данные 1 процессору и переходит в состояние ожидания данных от 3 процессора, инициализация параллельного приложения на 1 процессоре произошла намного позже, чем на 0 процессоре, время получения данных от 0 процессора меньше, чем время передачи сообщения 2 процессору и т.д.
1 PROGRAM EXAMPLE
2 INCLUDE 'mpif.h'
3 INTEGER my_id, np, comm,ierr, status
4 INTEGER next, prev
5 REAL*8 Buf
6 CALL MPI_Init(ierr)
7 comm=MPI_COMM_WORLD
8 CALL MPI_Comm_Size(comm, np, ierr)
9 CALL MPI_Comm_Rank(comm, my_id, ierr)
10 Write(*,*)'Hello, ',my_id,' processor
11 * of ',np, 'processors'
12 next=my_id+1
13 prev=my_id-1
14 IF (my_id.EQ.0) Then
15 prev=np-1
16 End IF
17 IF (my_id.EQ.np-1) Then
18 next=0
19 End IF
20 IF (my_id.EQ.0) Then
21 Buf=1
22 CALL MPI_Send(Buf,1,MPI_REAL8,next,1,comm,ierr)
23 CALL MPI_Recv(Buf,1, MPI_REAL8,prev,1,
24 * comm,status,ierr)
25 Else
26 CALL MPI_Recv(Buf,1, MPI_REAL8,prev,1,
27 * comm,status,ierr)
28 Buf=Buf+1
29 CALL MPI_Send(Buf,1,MPI_REAL8,next,1,comm,ierr)
30 End IF
31 Write(*,*) my_id,': Buf=',Buf
32 CALL MPI_Finalize(ierr)
33 STOP
34 END
Рис. 20. Пример пересылки данных между процессорами с использованием топологии ”кольцо”
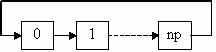
Рис. 21. Передача данных по “кольцу”
Более детально операции обмена сообщениями будут рассмотрены в следующем разделе, а в заключении этого раздела приведем функцию, которая не входит в очерченный минимум, но которая важна для разработки эффективных программ. Речь идет о функции получения отсчета времени - таймере. С одной стороны, такие функции имеются в составе всех операционных систем, но, с другой стороны, существует полнейший произвол в их реализации. Опыт работы с различными операционными системами показывает, что при переносе приложений с одной платформы на другую первое (а иногда и единственное), что приходится переделывать, это обращения к функциям учета времени. Поэтому разработчики MPI, добиваясь полной независимости приложений от операционной среды, ввели и свои функции отсчета времени.
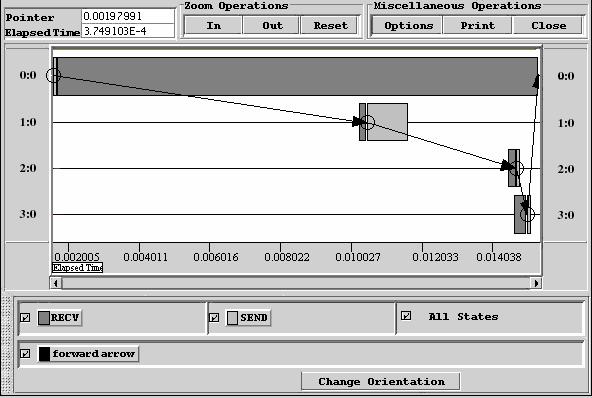
Рис. 22. Визуализация трассы исполнения параллельной программы пересылки данных с использованием топологии ”кольцо”
Функция отсчета времени (таймер) MPI_Wtime.
FORTRAN:
DOUBLE PRECISION MPI_WTIME()
C:
double MPI_Wtime(void)
Функция возвращает астрономическое время в секундах, прошедшее с некоторого момента в прошлом (точки отсчета). Гарантируется, что эта точка отсчета не будет изменена в течение жизни процесса. Для хронометрирования участка программы вызов функции делается в начале и конце участка и определяется разница между показаниями таймера.
Функция MPI_Wtick, имеющая точно такой же синтаксис, возвращает разрешение таймера (минимальное значение кванта времени).
На рис. 23 приведен предыдущий пример, но уже с использованием функций для замера времени (строки 12, 33).
1 Program EXAMPLE
2 INCLUDE 'mpif.h'
3 PARAMETER (max=100)
4 INTEGER my_id, np, comm,ierr, status
5 INTEGER next, prev
6 REAL*8 Buf(max)
7 DOUBLE PRECISION start_time, end_time
8 CALL MPI_Init(ierr)
9 comm=MPI_COMM_WORLD
10 CALL MPI_Comm_Size(comm, np, ierr)
11 CALL MPI_Comm_Rank(comm, my_id, ierr)
12 start_time=MPI_Wtime()
13 next=my_id+1
14 prev=my_id-1
15 IF (my_id.EQ.0) Then
16 prev=np-1
17 End IF
18 IF (my_id.EQ.np-1) Then
19 next=0
20 End IF
21 IF (my_id.EQ.0) Then
22 Buf(1)=1
23 CALL MPI_Send(Buf,np,MPI_REAL8,next,1,comm,ierr)
24 CALL MPI_Recv(Buf,np, MPI_REAL8,prev,
25 * 1,comm,status,ierr)
26 Else
27 CALL MPI_Recv(Buf,np, MPI_REAL8,prev,
28 * 1,comm,status,ierr)
29 Buf(my_id+1)=Buf(prev+1)+1
30 CALL MPI_Send(Buf,np,MPI_REAL8,next,1,comm,ierr)
31 End IF
32 IF (my_id.EQ.0) Then
33 Write(*,*) my_id,': Buf=',(Buf(j),j=1,np)
34 End IF
35 end_time=MPI_Wtime()
36 Write(*,*) my_id,': Time when processors work',
37 * end_time-start_time
38 CALL MPI_Finalize(ierr)
39 STOP
40 END
Рис. 23. Пример использования функций для замера времени