Набор операций типа “точка-точка” является достаточным для программирования любых алгоритмов, однако MPI вряд ли бы завоевал такую популярность, если бы ограничивался только этим набором коммуникационных операций. Одной из наиболее привлекательных сторон MPI является наличие широкого набора коллективных операций, которые берут на себя выполнение наиболее часто встречающихся при программировании действий. Например, часто возникает потребность разослать некоторую переменную или массив из одного процессора всем остальным. Каждый программист может написать такую процедуру с использованием операций Send/Recv, однако гораздо удобнее воспользоваться коллективной операцией MPI_Bcast. Причем гарантировано, что эта операция будет выполняться гораздо эффективнее, поскольку MPI-функция реализована с использованием внутренних возможностей коммуникационной среды. Главное отличие коллективных операций от операций типа “точка-точка” состоит в том, что в них всегда участвуют все процессы, связанные с некоторым коммуникатором. Несоблюдение этого правила приводит либо к аварийному завершению задачи, либо к еще более неприятному зависанию задачи.
Набор коллективных операций включает:
- синхронизацию всех процессов с помощью барьеров (MPI_Barrier);
- коллективные коммуникационные операции;
- глобальные вычислительные операции.
Коллективные коммуникационные операции реализуют следующее:
- рассылку информации от одного процесса всем остальным членам некоторой области связи (MPI_Bcast);
- сборку (gather) распределенного по процессам массива в один массив с сохранением его в адресном пространстве выделенного (root) процесса (MPI_Gather, MPI_Gatherv);
- сборку (gather) распределенного массива в один массив с рассылкой его всем процессам некоторой области связи (MPI_Allgather, MPI_Allgatherv);
- разбиение массива и рассылку его фрагментов (scatter) всем процессам области связи (MPI_Scatter, MPI_Scatterv);
- совмещенную операцию Scatter/Gather (All-to-All), каждый процесс делит данные из своего буфера передачи и разбрасывает фрагменты всем остальным процессам, одновременно собирая фрагменты, посланные другими процессами в свой буфер приема (MPI_Alltoall, MPI_Alltoallv).
Глобальные вычислительные операции (sum, min, max и др.) реализуются над данными, расположенными в адресных пространствах различных процессов:
- с сохранением результата в адресном пространстве одного процесса (MPI_Reduce);
- с рассылкой результата всем процессам (MPI_Allreduce);
- совмещенная операция Reduce/Scatter (MPI_Reduce_scatter);
- префиксная редукция (MPI_Scan).
Все коммуникационные подпрограммы, за исключением MPI_Bcast, представлены в двух вариантах:
- простой вариант, когда все части передаваемого сообщения имеют одинаковую длину и занимают смежные области в адресном пространстве процессов;
- "векторный" вариант предоставляет более широкие возможности по организации коллективных коммуникаций, снимая ограничения, присущие простому варианту как в части длин блоков, так и в части размещения данных в адресном пространстве процессов. Векторные варианты отличаются дополнительным символом "v" в конце имени функции.
- Отличительные особенности коллективных операций:
- коллективные коммуникации не взаимодействуют с коммуникациями типа “точка-точка”;
- коллективные коммуникации выполняются в режиме с блокировкой. Возврат из подпрограммы в каждом процессе происходит тогда, когда его участие в коллективной операции завершилось, однако это не означает, что другие процессы завершили операцию;
- количество получаемых данных должно быть равно количеству посланных данных.
Типы элементов посылаемых и получаемых сообщений должны совпадать.
Сообщения не имеют идентификаторов.
Примечание. В данном разделе часто будут использоваться понятия буфер обмена, буфер передачи, буфер приема. Не следует понимать эти понятия в буквальном смысле - как некую специальную область памяти, куда помещаются данные перед вызовом коммуникационной функции. На самом деле, это, как правило, обычные массивы, используемые в программе, и которые непосредственно могут участвовать в коммуникационных операциях. В вызовах подпрограмм передается адрес начала непрерывной области памяти, которая будет участвовать в операции обмена.
Изучение коллективных операций начнем с рассмотрения двух функций, стоящих особняком: MPI_Barrier и MPI_Bcast.
Функция синхронизации процессов MPI_Barrier блокирует работу вызвавшего ее процесса до тех пор, пока все другие процессы группы также не вызовут эту функцию. Завершение работы этой функции возможно только всеми процессами одновременно (все процессы "преодолевают барьер" одновременно).
FORTRAN:
INTEGER COMM, IERR
MPI_BARRIER(COMM, IERR)
C:
int MPI_Barrier(MPI_Comm comm )
Входные параметры:
|
comm |
- |
коммуникатор. |
Синхронизация с помощью барьеров используется, например, для завершения всеми процессами некоторого этапа решения задачи, результаты которого будут использоваться на следующем этапе. Использование барьера гарантирует, что ни один из процессов не приступит раньше времени к выполнению следующего этапа, пока результат работы предыдущего не будет окончательно сформирован. Неявную синхронизацию процессов выполняет любая коллективная функция.
Широковещательная рассылка данных выполняется с помощью функции MPI_Bcast. Процесс с номером root рассылает сообщение из своего буфера передачи всем процессам области связи коммуникатора comm.
FORTRAN:
<type> BUFFER(*)
INTEGER COUNT, DATATYPE, ROOT, COMM, IERR
MPI_BCAST(BUFFER, COUNT, DATATYPE, ROOT, COMM, IERR)
С:
int MPI_Bcast(void* buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm )
Входные параметры:
|
buffer |
- |
адрес начала расположения в памяти рассылаемых данных; |
|
count |
- |
число посылаемых элементов; |
|
datatype |
- |
тип посылаемых элементов; |
|
root |
- |
номер процесса-отправителя; |
|
comm |
- |
коммуникатор. |
Выходные параметры:
|
buffer |
- |
адрес начала расположения в памяти рассылаемых данных. |
После завершения подпрограммы каждый процесс в области связи коммуникатора comm, включая и самого отправителя, получит копию сообщения от процесса-отправителя root.
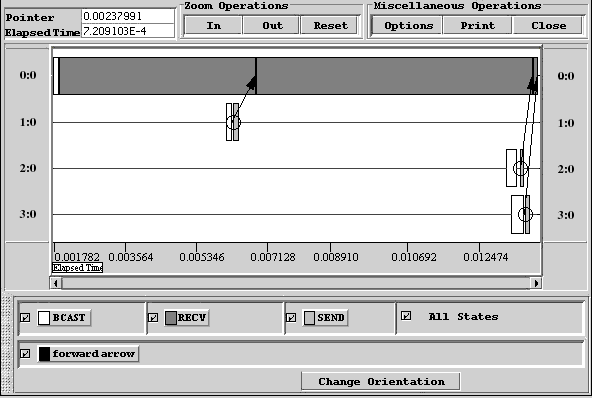
На рис. 26 приведен пример с использованием функции MPI_BCAST. На нулевом процессоре создается массив данных и с помощью функции MPI_BCAST рассылается всем процессорам, полученный массив изменяется в зависимости от номера процессора и с помощью функций SEND, RECV возвращается на нулевой процессор. Визуализация трассы исполнения параллельной программы приведена на рис. 27.
1 program EXAMPLE
2 INCLUDE 'mpif.h'
3 PARAMETER (max=100)
4 integer my_id, np, comm,ierr, status(MPI_STATUS_SIZE)
5 integer next, prev
6 real*8 Buf(max)
7 call MPI_Init(ierr)
8 comm=MPI_COMM_WORLD
9 call MPI_Comm_Size(comm, np, ierr)
10 call MPI_Comm_Rank(comm, my_id, ierr)
11 Write(*,*) 'Hello, ',my_id,' processor of '
12 * ,np, '...work'
13 next=my_id+1
14 prev=my_id-1
15 if (my_id.eq.0) then
16 prev=np-1
17 end if
18 if (my_id.eq.np-1) then
19 next=0
20 end if
21 if (my_id.eq.0) then
22 do i=1,np
23 buf(i)=i
24 end do
25 end if
26 call MPI_BCAST(buf,np,MPI_REAL8,0,comm,ierr)
27 if (my_id.eq.0) then
28 do i=1,np-1
29 call MPI_Recv(Buf(i+1),1, MPI_REAL8,i,1,
30 * comm,status,ierr)
31 end do
32 else
33 Buf(my_id+1)=Buf(my_id+1)+1
34 call MPI_Send(Buf(my_id+1),1,MPI_REAL8,0,1,comm,ierr)
35 end if
36 if (my_id.eq.0) then
37 Write(*,*) my_id,': Buf=',(Buf(j),j=1,np)
38 end if
39 call MPI_Finalize(ierr)
40 stop
41 end
Рис. 26. Пример использования функции MPI_BCAST
Функции сбора блоков данных от всех процессов группы
Семейство функций сбора блоков данных от всех процессов группы состоит из четырех подпрограмм: MPI_Gather, MPI_Allgather, MPI_Gatherv, MPI_Allgatherv. Каждая из указанных подпрограмм расширяет функциональные возможности предыдущих.
Функция MPI_Gather производит сборку блоков данных, посылаемых всеми процессами группы, в один массив процесса с номером root. Длина блоков предполагается одинаковой. Объединение происходит в порядке увеличения номеров процессов-отправителей. То есть данные, посланные процессом i из своего буфера sendbuf, помещаются в i-ю порцию буфера recvbuf процесса root. Длина массива, в который собираются данные, должна быть достаточной для их размещения.
Рис. 27. Визуализация трассы исполнения параллельной программы пересылки данных
FORTRAN:
<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNT, SENDTYPE, RECVCOUNT, RECVTYPE
INTEGER ROOT, COMM, IER
MPI_GATHER(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF, RECVCOUNT, RECVTYPE, ROOT, COMM, IERR)
С:
int MPI_Gather(void* sendbuf, int sendcount, MPI_Datatype sendtype, void* recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm)
Входные параметры:
|
sendbuf |
- |
адрес начала размещения посылаемых данных; |
|
sendcount |
- |
число посылаемых элементов; |
|
sendtype |
- |
тип посылаемых элементов; |
|
recvcount |
- |
число элементов, получаемых от каждого процесса (используется только в процессе-получателе root); |
|
recvtype |
- |
тип получаемых элементов; |
|
root |
- |
номер процесса-получателя; |
|
comm |
- |
коммуникатор. |
Выходные параметры:
|
recvbuf |
- |
адрес начала буфера приема (используется только в процессе-получателе root). |
Тип посылаемых элементов sendtype должен совпадать с типом recvtype получаемых элементов, а число sendcount должно равняться числу recvcount. То есть recvcount в вызове из процесса root – это число собираемых от каждого процесса элементов, а не общее количество собранных элементов. Графическая интерпретация операции Gather представлена на рис. 28, листинг программы – рис. 29, визуализация трассы исполнения параллельной программы приведена на рис. 30.
Рис. 28. Графическая интерпретация операции Gather
1 PROGRAM EXAMPLE
2 INCLUDE 'mpif.h'
3 INTEGER my_id, np, comm,ierr, n
4 REAL*8 buf(100),rbuf(100)
5 CALL MPI_Init(ierr)
6 comm=MPI_COMM_WORLD
7 CALL MPI_Comm_Size(comm, np, ierr)
8 CALL MPI_Comm_Rank(comm, my_id, ierr)
9 Write(*,*) 'Hello, ',my_id,' processor of'
10 * ,np, 'processors'
11 IF (my_id.EQ.0) Then
12 read (*,*) N
13 End IF
14 do i=1,np
15 buf(i)=np*my_id+i
16 end do
17 CALL MPI_Gather(buf, np, MPI_REAL8, rbuf, np,
18 * MPI_REAL8, 0, comm,ierr)
19 IF (my_id.EQ.0) Then
20 do i=1,np*np
21 Write(*,*) my_id,': rBuf(',i,')=',rBuf(i)
22 end do
23 End IF
24 CALL MPI_Finalize(ierr)
25 STOP
26 END
Рис. 29. Пример программы с использованием функции MPI_Gather
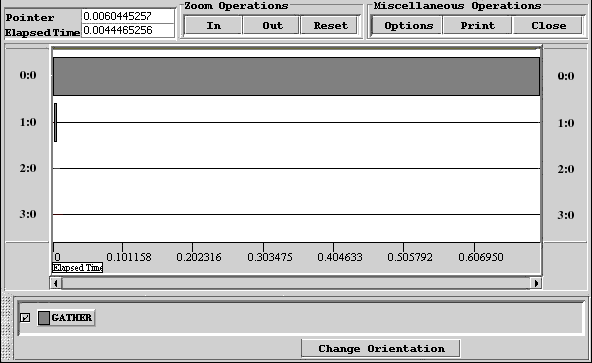
Рис. 30. Визуализация трассы исполнения параллельной программы пересылки данных
Функция MPI_Allgather выполняется так же, как MPI_Gather, но получателями являются все процессы группы. Данные, посланные процессом i из своего буфера sendbuf, помещаются в i-ю порцию буфера recvbuf каждого процесса. После завершения операции содержимое буферов приема recvbuf у всех процессов одинаково.
FORTRAN:
<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNT, SENDTYPE, RECVCOUNT, RECVTYPE
INTEGER COMM, IERROR
MPI_ALLGATHER(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF, RECVCOUNT, RECVTYPE, COMM, IERR)
C:
int MPI_Allgather(void* sendbuf, int sendcount, MPI_Datatype sendtype, void* recvbuf, int recvcount, MPI_Datatype recvtype, MPI_Comm comm)
Входные параметры:
|
sendbuf |
- |
адрес начала буфера посылки; |
|
sendcount |
- |
число посылаемых элементов; |
|
sendtype |
- |
тип посылаемых элементов; |
|
recvcount |
- |
число элементов, получаемых от каждого процесса; |
|
recvtype |
- |
тип получаемых элементов; |
|
comm |
- |
коммуникатор. |
Входные параметры:
|
recvbuf |
- |
адрес начала буфера приема. |
Схема выполнения операции Allgater представлена на рис. 31.
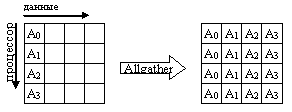
Рис. 31. Схема выполнения операции Аllgather
1 PROGRAM EXAMPLE
2 INCLUDE 'mpif.h'
3 INTEGER my_id, np, comm, ierr
4 CALL MPI_Init(ierr)
5 comm=MPI_COMM_WORLD
6 CALL MPI_Comm_Size(comm, np, ierr)
7 CALL MPI_Comm_Rank(comm, my_id, ierr)
8 Write(*,*) 'Hello, ',my_id,' processor of '
9 * ,np, ' processors'
10 DO I=1,2
11 BUF(I)=MY_ID+I
12 END DO
13 CALL MPI_ALLGATHER(BUF, 2, MPI_REAL8, RBUF, 2,
14 * MPI_REAL8, COMM,IERR)
15 IF (MY_ID.EQ.0) THEN
16 DO I=1,2*NP
17 WRITE(*,*) MY_ID,': RBUF(',I,')=',RBUF(I)
18 END DO
19 END IF
20 CALL MPI_Finalize(ierr)
21 STOP
22 END
Рис. 32. Пример программы с использованием функции MPI_AllGather
Функция MPI_Gatherv позволяет собирать блоки с разным числом элементов от каждого процесса, так как количество элементов, принимаемых от каждого процесса, задается индивидуально с помощью массива recvcounts. Эта функция обеспечивает также большую гибкость при размещении данных в процессе-получателе, благодаря введению в качестве параметра массива смещений displs.
FORTRAN:
<type> SENDBUF(*), RBUF(*)
INTEGER SENDCOUNT, SENDTYPE, RECVCOUNTS(*), DISPLS(*)
INTEGER RECVTYPE, ROOT, COMM, IERR
MPI_GATHERV(SENDBUF, SENDCOUNT, SENDTYPE, RBUF, RECVCOUNTS, DISPLS, RECVTYPE, ROOT, COMM, IERR)
C:
int MPI_Gatherv(void* sendbuf, int sendcount, MPI_Datatype sendtype, void* rbuf, int *recvcounts, int *displs, MPI_Datatype recvtype, int root, MPI_Comm comm)
Входные параметры:
|
sendbuf |
- |
адрес начала буфера передачи; |
|
sendcount |
- |
число посылаемых элементов; |
|
sendtype |
- |
тип посылаемых элементов; |
|
recvcounts |
- |
целочисленный массив (размер равен числу процессов в группе), i-й элемент которого определяет число элементов, которое должно быть получено от процесса i; |
|
displs |
- |
ацелочисленный массив (размер равен числу процессов в группе), i-ое значение определяет смещение i-го блока данных относительно начала rbuf; |
|
recvtype |
- |
тип получаемых элементов; |
|
root |
- |
номер процесса-получателя; |
|
comm |
- |
коммуникатор. |
Выходные параметры:
|
recvbuf |
- |
адрес начала буфера приема. |
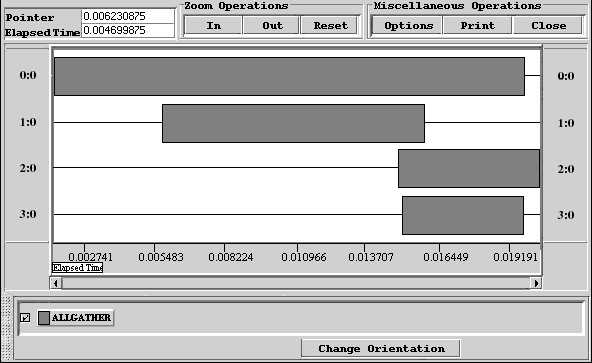
Рис. 33. Визуализация трассы исполнения параллельной программы
Сообщения помещаются в буфер приема процесса root в соответствии с номерами посылающих процессов, а именно, данные, посланные процессом i, размещаются в адресном пространстве процесса root, начиная с адреса rbuf + displs[i]. Графическая интерпретация операции Gatherv представлена на рис. 34.
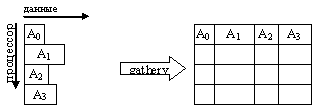
Рис. 34. Графическая интерпретация операции Gatherv
Функция MPI_Allgatherv является аналогом функции MPI_Gatherv, но сборка выполняется всеми процессами группы. Поэтому в списке параметров отсутствует параметр root.
FORTRAN:
<type>SENDBUF(*),RBUF(*)
INTEGER SENDCOUNT, SENDTYPE, RECVCOUNTS(*), DISPLS(*)
INTEGER RECVTYPE, COMM, IERR
MPI_ALLGATHERV(SENDBUF, SENDCOUNT, SENDTYPE, RBUF, RECVCOUNTS, DISPLS, RECVTYPE, COMM, IERR)
C:
int MPI_Allgatherv(void* sendbuf, int sendcount, MPI_Datatype sendtype, void* rbuf, int *recvcounts, int *displs, MPI_Datatype recvtype, MPI_Comm comm)
Входные параметры:
|
sendbuf |
- |
адрес начала буфера приема; |
|
sendcount |
- |
число посылаемых элементов; |
|
sendtype |
- |
тип посылаемых элементов; |
|
recvcounts |
- |
целочисленный массив (размер равен числу процессов в группе), содержащий число элементов, которое должно быть получено от каждого процесса; |
|
displs |
- |
целочисленный массив (размер равен числу процессов в группе), i-ое значение определяет смещение относительно начала rbuf i-го блока данных; |
|
recvtype |
- |
тип получаемых элементов; |
|
comm |
- |
коммуникатор. |
Выходные параметры:
|
recvbuf |
- |
адрес начала буфера приема. |
Функции распределения блоков данных по всем процессам группы
Семейство функций распределения блоков данных по всем процессам группы состоит из двух подпрограмм: MPI_Scatter и MPI_Scaterv.
Функция MPI_Scatter разбивает сообщение из буфера посылки процесса root на равные части размером sendcount и посылает i-ю часть в буфер приема процесса с номером i (в том числе и самому себе). Процесс root использует оба буфера (посылки и приема), поэтому в вызываемой им подпрограмме все параметры являются существенными. Остальные процессы группы с коммуникатором comm являются только получателями, поэтому для них параметры, специфицирующие буфер посылки, не существенны.
FORTRAN:
<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNT, SENDTYPE, RECVCOUNT, RECVTYPE
INTEGER ROOT, COMM, IERR
MPI_SCATTER(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF, RECVCOUNT, RECVTYPE, ROOT, COMM, IERR)
C:
int MPI_Scatter(void* sendbuf, int sendcount, MPI_Datatype sendtype, void* recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm)
Входные параметры:
|
sendbuf |
- |
адрес начала размещения блоков распределяемых данных (используется только в процессе-отправителе root); |
|
sendcount |
- |
число элементов, посылаемых каждому процессу; |
|
sendtype |
- |
тип посылаемых элементов; |
|
recvcount |
- |
число получаемых элементов; |
|
recvtype |
- |
тип получаемых элементов; |
|
root |
- |
номер процесса-отправителя; |
|
comm |
- |
коммуникатор. |
Выходные параметры:
|
recvbuf |
- |
адрес начала буфера приема. |
Тип посылаемых элементов sendtype должен совпадать с типом recvtype получаемых элементов, а число посылаемых элементов sendcount должно равняться числу принимаемых recvcount. Следует обратить внимание, что значение sendcount в вызове из процесса root - это число посылаемых каждому процессу элементов, а не общее их количество. Операция Scatter является обратной по отношению к Gather. На рис. 35 представлена графическая интерпретация операции Scatter.
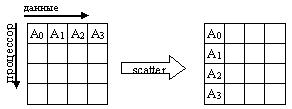
Рис. 35. Графическая интерпретация операции Scatter
1 PROGRAM EXAMPLE
2 INCLUDE 'mpif.h'
3 INTEGER my_id, np, comm,ierr, n
4 REAL*8 buf, rbuf(100)
5 CALL MPI_Init(ierr)
6 comm=MPI_COMM_WORLD
7 CALL MPI_Comm_Size(comm, np, ierr)
8 CALL MPI_Comm_Rank(comm, my_id, ierr)
9 Write(*,*) 'Hello, ',my_id,' processor of '
10 * ,np, 'processors'
11 IF (my_id.EQ.0) Then
12 do i=1, np
13 rbuf(i)=i
14 end do
15 END IF
16 CALL MPI_Scatter (rbuf, 1, MPI_REAL8, buf, 1,
17 * MPI_REAL8, 0, comm, ierr)
18 Write(*,*) my_id,': Buf'=',Buf
19 CALL MPI_Finalize(ierr)
20 STOP
21 END
Рис. 36. Пример использования функции MPI_Scatter
Функция MPI_Scaterv является векторным вариантом функции MPI_Scatter, позволяющим посылать каждому процессу различное количество элементов. Начало расположения элементов блока, посылаемого i-му процессу, задается в массиве смещений displs, а число посылаемых элементов – в массиве sendcounts. Эта функция является обратной по отношению к функции MPI_Gatherv.
FORTRAN:
<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNTS(*), DISPLS(*), SENDTYPE, RECVCOUNT, RECVTYPE, ROOT, COMM, IERR
MPI_SCATTERV(SENDBUF, SENDCOUNTS, DISPLS, SENDTYPE, RECVBUF, RECVCOUNT, RECVTYPE, ROOT, COMM, IERR)
C:
int MPI_Scatterv(void* sendbuf, int *sendcounts, int *displs, MPI_Datatype sendtype, void* recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm)
Входные параметры:
|
sendbuf |
- |
адрес начала буфера посылки (используется только в процессе-отправителе root); |
|
sendcounts |
- |
целочисленный массив (размер равен числу процессов в группе), содержащий число элементов, посылаемых каждому процессу; |
|
displs |
- |
целочисленный массив (размер равен числу процессов в группе), i-ое значение определяет смещение относительно начала sendbuf для данных, посылаемых процессу i; |
|
sendtype |
- |
тип посылаемых элементов; |
|
recvcount |
- |
число получаемых элементов; |
|
recvtype |
- |
тип получаемых элементов; |
|
root |
- |
номер процесса-отправителя; |
|
сomm |
- |
коммуникатор. |
Входные параметры:
|
recvbuf |
- |
адрес начала буфера приема. |
На рис. 37 представлена графическая интерпретация операции Scatterv.
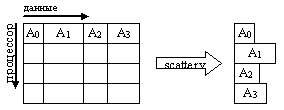
Рис. 37. Графическая интерпретация операции Scatterv
Совмещенные коллективные операции
Функция MPI_Alltoall совмещает в себе операции Scatter и Gather и является, по сути дела, расширением операции Allgather, когда каждый процесс посылает различные данные разным получателям. Процесс i посылает j-ый блок своего буфера sendbuf процессу j, который помещает его в i-ый блок своего буфера recvbuf. Количество посланных данных должно быть равно количеству полученных данных для каждой пары процессов.
FORTRAN:
<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNT, SENDTYPE, RECVCOUNT, RECVTYPE
INTEGER COMM, IERR
MPI_ALLTOALL(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF, RECVCOUNT, RECVTYPE, COMM, IERR)
C:
int MPI_Alltoall(void* sendbuf, int sendcount, MPI_Datatype sendtype, void* recvbuf, int recvcount, MPI_Datatype recvtype, MPI_Comm comm)
Входные параметры:
|
sendbuf |
- |
адрес начала буфера посылки; |
|
sendcount |
- |
число посылаемых элементов; |
|
sendtype |
- |
тип посылаемых элементов; |
|
recvcount |
- |
число элементов, получаемых от каждого процесса; |
|
recvtype |
- |
тип получаемых элементов; |
|
comm |
- |
коммуникатор. |
Выходные параметры:
|
recvbuf |
- |
адрес начала буфера приема. |
Схема выполнения операции Alltoall представлена на рис. 38.
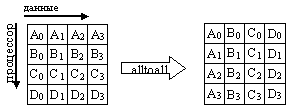
Рис. 38. Схема выполнения операции Аlltoall
Функция MPI_Alltoallv реализует векторный вариант операции Alltoall, допускающий передачу и прием блоков различной длины с более гибким размещением передаваемых и принимаемых данных.
Глобальные вычислительные операции над распределенными данными
В параллельном программировании математические операции над блоками данных, распределенных по процессорам, называют глобальными операциями редукции. В общем случае операцией редукции называется операция, аргументом которой является вектор, а результатом - скалярная величина, полученная применением некоторой математической операции ко всем компонентам вектора. В частности, если компоненты вектора расположены в адресных пространствах процессов, выполняющихся на различных процессорах, то в этом случае говорят о глобальной (параллельной) редукции. Например, пусть в адресном пространстве всех процессов некоторой группы процессов имеются копии переменной var (необязательно имеющие одно и то же значение), тогда применение к ней операции вычисления глобальной суммы или, другими словами, операции редукции SUM возвратит одно значение, которое будет содержать сумму всех локальных значений этой переменной. Использование этих операций является одним из основных средств организации распределенных вычислений.
В MPI глобальные операции редукции представлены в нескольких вариантах:
· с сохранением результата в адресном пространстве одного процесса (MPI_Reduce);
· с сохранением результата в адресном пространстве всех процессов (MPI_Allreduce);
· префиксная операция редукции, которая в качестве результата операции возвращает вектор. i-я компонента этого вектора является результатом редукции первых i компонент распределенного вектора (MPI_Scan);
· совмещенная операция Reduce/Scatter (MPI_Reduce_scatter).
Функция MPI_Reduce выполняется следующим образом. Операция глобальной редукции, указанная параметром (ОР), выполняется над первыми элементами входного буфера, и результат посылается в первый элемент буфера приема процесса root. Затем то же самое делается для вторых элементов буфера и т.д.
FORTRAN:
<type> SENDBUF(*), RECVBUF(*)
INTEGER COUNT, DATATYPE, OP, ROOT, COMM, IERR
MPI_REDUCE(SENDBUF, RECVBUF, COUNT, DATATYPE, OP, ROOT, COMM, IERR)
С:
int MPI_Reduce(void* sendbuf, void* recvbuf, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm)
Входные параметры:
|
recvbuf |
- |
адрес начала входного буфера; |
|
count |
- |
число элементов во входном буфере; |
|
datatype |
- |
тип элементов во входном буфере; |
|
op |
- |
операция, по которой выполняется редукция; |
|
root |
- |
номер процесса-получателя результата операции; |
|
comm |
- |
коммуникатор. |
Выходные параметры:
|
recvbuf |
- |
адрес начала буфера результатов (используется только в процессе-получателе root). |
На рис. 39 представлена графическая интерпретация операции Reduce. На данной схеме операция "+" означает любую допустимую операцию редукции.
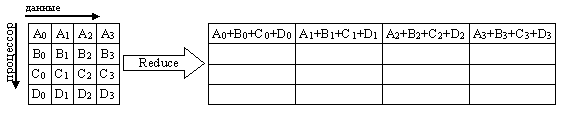
Рис. 39. Графическая интерпретация операции Reduce
1 PROGRAM EXAMPLE
2 INCLUDE 'mpif.h'
3 INTEGER my_id, np, comm, ierr
4 REAL*8 rbuf,sbuf
5 CALL MPI_Init(ierr)
6 comm=MPI_COMM_WORLD
7 CALL MPI_Comm_Size(comm, np, ierr)
8 CALL MPI_Comm_Rank(comm, my_id, ierr)
9 Write(*,*) 'Hello, ',my_id,' processor of '
10 * ,np, ' processors'
11 do i=1+my_id,100,np
12 sbuf=sbuf+i
13 end do
14 CALL MPI_Reduce(sbuf,rbuf,1,MPI_REAL8,MPI_SUM,0,
15 * comm,ierr)
16 IF (my_id.EQ.0) Then
17 Write(*,*) my_id,': rbuf
18 END IF
19 CALL MPI_Finalize(ierr)
20 STOP
21 END
Рис. 40. Пример использования MPI_Reduce
В качестве операции (ОР) можно использовать либо одну из предопределенных операций, либо операцию, сконструированную пользователем. Все предопределенные операции являются ассоциативными и коммутативными. Сконструированная пользователем операция, по крайней мере, должна быть ассоциативной. Порядок редукции определяется номерами процессов в группе. Тип datatype элементов должен быть совместим с операцией (ОР). В таблице 13 представлен перечень предопределенных операций, которые могут быть использованы в функциях редукции MPI.
Таблица 13
Название |
Операция |
Разрешенные типы |
MPI_MAX |
Максимум |
C integer, FORTRAN integer, |
MPI_SUM |
Сумма |
C integer, FORTRAN integer, |
| MPI_LAND MPI_LOR MPI_LXOR |
Логическое AND |
C integer, Logical |
MPI_BAND |
Поразрядное AND |
C integer, FORTRAN integer, |
MPI_MAXLOC |
Максимальное значение и его индекс |
Специальные типы для этих функций |
В таблице 13 используются следующие обозначения:
C integer: |
MPI_INT, MPI_LONG, MPI_SHORT, MPI_UNSIGNED_SHORT, MPI_UNSIGNED, MPI_UNSIGNED_LONG |
FORTRAN integer: |
MPI_INTEGER |
Floating point: |
MPI_FLOAT, MPI_DOUBLE, MPI_REAL, MPI_DOUBLE_PRECISION, MPI_LONG_DOUBLE |
Logical: |
MPI_LOGICAL |
Complex: |
MPI_COMPLEX |
Byte: |
MPI_BYTE |
Операции MAXLOC и MINLOC выполняются над специальными парными типами, каждый элемент которых хранит две величины: значение, по которому ищется максимум или минимум, и индекс элемента. В MPI имеется 9 таких предопределенных типов.
|
C: |
|||
MPI_FLOAT_INT |
float |
and |
int |
MPI_DOUBLE_INT |
double |
and |
int |
MPI_LONG_INT |
long |
and |
int |
MPI_2INT |
int |
and |
int |
MPI_SHORT_INT |
short |
and |
int |
MPI_LONG_DOUBLE_INT |
long double |
and |
int |
|
FORTRAN: |
|||
MPI_2REAL |
REAL |
and |
REAL |
MPI_2DOUBLE_PRECISION |
DOUBLE PRECISION |
and |
DOUBLE PRECISION |
MPI_2INTEGER |
INTEGER |
and |
INTEGER |
Функция MPI_Allreduce сохраняет результат редукции в адресном пространстве всех процессов, поэтому в списке параметров функции отсутствует идентификатор корневого процесса root. В остальном, набор параметров такой же, как и в предыдущей функции.
FORTRAN:
<type> SENDBUF(*), RECVBUF(*)
INTEGER COUNT, DATATYPE, OP, COMM, IERR
MPI_ALLREDUCE(SENDBUF, RECVBUF, COUNT, DATATYPE, OP, COMM, IERR)
С:
int MPI_Allreduce(void* sendbuf, void* recvbuf, int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
Входные параметры:
|
sendbuf |
- |
адрес начала входного буфера; |
|
count |
- |
число элементов во входном буфере; |
|
datatype |
- |
тип элементов во входном буфере; |
|
op |
- |
операция, по которой выполняется редукция; |
|
comm |
- |
коммуникатор. |
Выходные параметры:
|
recvbuf |
- |
адрес начала буфера приема. |
На рис. 41 представлена графическая интерпретация операции Allreduce.
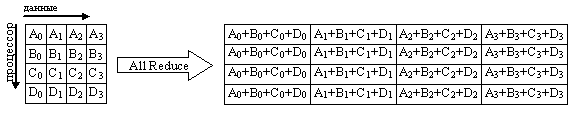
Рис. 41. Графическая интерпретация операции Allreduce
1 PROGRAM EXAMPLE
2 INCLUDE 'mpif.h'
3 INTEGER my_id, np, comm, ierr
4 REAL*8 rbuf(100),sbuf(100)
5 CALL MPI_Init(ierr)
6 comm=MPI_COMM_WORLD
7 CALL MPI_Comm_Size(comm, np, ierr)
8 CALL MPI_Comm_Rank(comm, my_id, ierr)
9 Write(*,*) 'Hello, ',my_id,' processor of '
10 * ,np, ' processors'
11 do i=1,np
12 sbuf(i)=my_id
13 end do
14 CALL MPI_ALLReduce(sbuf,rbuf,np,MPI_REAL8,MPI_SUM,
15 * comm,ierr)
16 do i=1,np
17 Write(*,*) my_id,': rbuf(i)
18 end do
19 CALL MPI_Finalize(ierr)
20 STOP
21 END
Рис. 42. Пример использования MPI_AllReduce
Функция MPI_Reduce_scatter совмещает в себе операции редукции и распределения результата по процессам.
FORTRAN:
<type> SENDBUF(*), RECVBUF(*)
INTEGER RECVCOUNTS(*), DATATYPE, OP, COMM, IERR
MPI_REDUCE_SCATTER(SENDBUF, RECVBUF, RECVCOUNTS, DATATYPE, OP, COMM, IERR)
С:
MPI_Reduce_scatter(void* sendbuf, void* recvbuf, int *recvcounts, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
Входные параметры:
|
sendbuf |
- |
адрес начала входного буфера; |
|
revcount |
- |
массив, в котором задаются размеры блоков, посылаемых процессам; |
|
datatype |
- |
тип элементов во входном буфере; |
|
op |
- |
операция, по которой выполняется редукция; |
|
comm |
- |
коммуникатор. |
Выходные параметры:
|
recvbuf |
- |
адрес начала буфера приема. |
Функция MPI_Reduce_scatter отличается от MPI_Allreduce тем, что результат операции разрезается на непересекающиеся части по числу процессов в группе, i-ая часть посылается i-ому процессу в его буфер приема. Длины этих частей задает третий параметр, являющийся массивом. На рис. 43 представлена графическая интерпретация операции Reduce_scatter.

Рис. 43. Графическая интерпретация операции Reduce_scatter
1 PROGRAM EXAMPLE
2 INCLUDE 'mpif.h'
3 INTEGER my_id, np, comm, ierr, bufc(100)
4 real*8 sbuf(100), rbuf(100)
5 CALL MPI_Init(ierr)
6 comm=MPI_COMM_WORLD
7 CALL MPI_Comm_Size(comm, np, ierr)
8 CALL MPI_Comm_Rank(comm, my_id, ierr)
9 Write(*,*) 'Hello, ',my_id,' processor of '
10 * ,np, ' processors'
11 do i=1,np
12 sbuf(i)=my_id
13 BUFC(i)=1
14 end do
15 CALL MPI_Reduce_SCAtter (sbuf,RBUF, bufC, MPI_REAL8,
16 * MPI_SUM, comm,ierr)
17 Write(*,*) my_id,': rbuf(1)
18 CALL MPI_Finalize(ierr)
19 STOP
20 END
Рис. 44. Пример использования MPI_Reduce_scatter
Функция MPI_Scan выполняет префиксную редукцию. Параметры такие же, как в MPI_Allreduce, но получаемые каждым процессом результаты отличаются друг от друга. Операция пересылает в буфер приема i-го процесса редукцию значений из входных буферов процессов с номерами 0, ... i включительно.
FORTRAN:
<type>SENDBUF(*), RECVBUF(*)
INTEGER COUNT, DATATYPE, OP, COMM, IERR
MPI_SCAN(SENDBUF, RECVBUF, COUNT, DATATYPE, OP, COMM, IERR)
С:
int MPI_Scan(void* sendbuf, void* recvbuf, int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
Входные параметры:
|
sendbuf |
- |
адрес начала входного буфера; |
|
count |
- |
число элементов во входном буфере; |
|
datatype |
- |
тип элементов во входном буфере; |
|
op |
- |
операция, по которой выполняется редукция; |
|
comm |
- |
коммуникатор. |
Выходные параметры:
|
recvbuf |
- |
адрес начала буфера приема. |
На рис. 45 представлена графическая интерпретация операции Scan.

Рис. 45. Графическая интерпретация операции Scan