Одной из целей при конструировании
параллельных алгоритмов является достижение по возможности большего ускорения;
в идеальном случае
![]() .
Однако мы уже видели на примере сложения n
чисел, что эта ситуация не всегда достижима. В самом деле, максимальное
ускорение можно получить только для задач, по существу тривиальных.
.
Однако мы уже видели на примере сложения n
чисел, что эта ситуация не всегда достижима. В самом деле, максимальное
ускорение можно получить только для задач, по существу тривиальных.
Главные факторы, обусловливающие отклонение от максимального ускорения, таковы:
1. Отсутствие максимального параллелизма в алгоритме и/или несбалансированность нагрузки процессоров.
2. Обмены, конфликты памяти и время синхронизации.
Хотя задержки, связанные с синхронизацией, обменами и конфликтами памяти, по своей природе весьма различны, их воздействие на общий процесс вычисления одинаково: они замедляют его на время, необходимое для подготовки данных, нужных для дальнейшего счета. Поэтому иногда следует объединять все три фактора задержки, как это сделано в следующем определении.
Определение 7. Временем подготовки данных называется задержка, вызванная обменами, конфликтами памяти или синхронизацией и необходимая для того, чтобы разместить данные, требующиеся для продолжения вычислений, в соответствующих ячейках памяти.
Обратимся теперь к фактору отсутствия
максимального параллелизма. Он может проявляться по-разному. При сложении n
чисел мы видели, что на первом
этапе алгоритма параллелизм максимален, однако на каждом последующем этапе
степень параллелизма уменьшается вдвое. Таким образом, в большинстве случаев
средняя степень параллелизма алгоритма меньше
![]() .
.
Рассмотрим теперь формальную модель ускорения, в которой
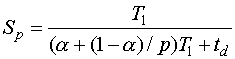 ,
,
где ![]() - время,
затрачиваемое на реализацию алгоритма на одном процессоре,
- время,
затрачиваемое на реализацию алгоритма на одном процессоре,
![]() - доля операций в
алгоритме, выполняемых одним процессором,
- доля операций в
алгоритме, выполняемых одним процессором,
![]() - доля операций,
выполняемых всеми
- доля операций,
выполняемых всеми
![]() процессорами,
процессорами,
![]() - общее время, требуемое для подготовки данных.
- общее время, требуемое для подготовки данных.
В случае если
![]() =0 и
=0 и
![]() =0, ускорение максимально
=0, ускорение максимально
![]() .
Предпосылки данного случая заключаются в том, что все операции выполняются с максимальным
параллелизмом и отсутствуют задержки на подготовку данных.
.
Предпосылки данного случая заключаются в том, что все операции выполняются с максимальным
параллелизмом и отсутствуют задержки на подготовку данных.
В случае
![]() =0 получаем формулу, выражающую закон Амдаля
=0 получаем формулу, выражающую закон Амдаля
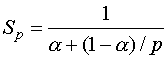 .
.
Предположим, что
![]() , то есть половина
операций в алгоритме может выполняться параллельно, а половина нет. Тогда
ускорение принимает вид
, то есть половина
операций в алгоритме может выполняться параллельно, а половина нет. Тогда
ускорение принимает вид
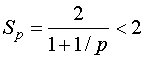 .
.
Таким образом, независимо от количества процессоров и даже при игнорировании всех затрат на подготовку данных ускорение параллельного алгоритма всегда меньше 2.