Министерство общего и профессионального образования РФ
Кемеровский государственный университет
Кафедра ЮНЕСКО по новым информационным технологиям
Рабочая программа по спецкурсу
“Многопроцессорные вычислительные комплексы и параллельное программирование”
для специальности 01.01(01.02) – (ДО)
для специальности 35.15 – (ДО)
|
Факультет |
Математический |
|
Курс |
4 |
|
Семестр |
7 |
|
Лекции |
36 часов |
|
Лаб. занятия |
36 часов |
|
Семестровое задание |
20 часов |
|
Консультация |
2 часа |
|
Экзамен |
6 часов |
|
Всего часов |
100 часов |
Составитель: доцент, к.ф.-м.н. Стуколов С.В.
Кемерово, 2004г.
Важнейшей составной частью создания и внедрения высокопроизводительных технологий является существенное расширение компьютерного образования и подготовка квалифицированных специалистов в этой области. В КемГУ подготовка специалистов ведется на Кафедре ЮНЕСКО по новым информационным технологиям, на дисциплинах специализации, для студентов математического факультета, начиная с третьего курса по направлениям:
• в области организации распределенных вычислительных сред и удаленного доступа к ним;
• по организации высокопроизводительных вычислений для заранее поставленной задачи.
В рамках первого направления осуществляется подготовка квалифицированных системных программистов для технического и программного обеспечения высокопроизводительных вычислительных систем, кадров по созданию телекоммуникационной среды высокопроизводительных технологий и персонала по обслуживанию локальных и глобальных компьютерных сетей. Программа подготовки специалистов по второму направлению включает следующие основные разделы:
• архитектура современных многопроцессорных вычислительных машин;
• системное программное обеспечение параллельных ЭВМ и сетей;
• технология программирования на параллельных ЭВМ;
• параллельные алгоритмы вычислительной математики;
• математическое моделирование и вычислительный эксперимент.
На завершающей стадии подготовки специалистов в рамках указанной специализации предусматривается выполнение курсовых проектов, связанных с предполагаемой темой дипломной работы.
Цели и задачи данного курса – ознакомить студентов с современными вычислительными системами, методами распараллеливания алгоритмов, привить навыки параллельного программирования на Си и Фортране с использованием коммуникационной библиотеки MPI. В процессе прохождения курса студентами будет освоена технология создания вычислительного кластера на основе объединения сети ПК (база для проведения лабораторных занятий – компьютерный класс каф. Юнеско по НИТ), организация доступа к кластеру других пользователей, студенты научатся создавать параллельные программы и будут готовы к применению технологии параллельного программирования при решении ресурсоемких задач, поставленных в дипломных проектах.
Темы лекционных занятий
| 1. | Обзор существующих микропроцессоров и операционных систем | 2 часа |
| 2. | Основные направления развития высокопроизводительных компьютеров | 2 часа |
| 3. | Оценки производительности вычислительных систем | 2 часа |
| 4. | Классификация многопроцессорных систем | 2 часа |
| 5. | Две парадигмы параллельного программирования | 2 часа |
| 6. | Обзор коммуникационных библиотек и интерфейсов для организации параллельных вычислений | 2 часа |
| 7. | Параллельные языки и параллельные расширения. Средства автоматического распараллеливания программ. Специализированные библиотеки | 2 часа |
| 8. | Инструментальные системы. Отечественная разработка – система DVM | 2 часа |
| 9. | Обзор существующих кластерных систем в России и за рубежом (архитектура, стоимость, производительность) | 2 часа |
| 10. | Типовая организация вычислительного кластера на базе сети ПК | 2 часа |
| 11. | Степень параллелизма численного алгоритма. Ускорение параллельного алгоритма. Эффективность параллельного алгоритма | 2 часа |
| 12. | Закон Амдаля. Исследование свойств параллельного алгоритма | 2 часа |
| 13. | Алгоритм сдваивания. Параллельный алгоритм скалярного умножения векторов и его ускорение по сравнению с последовательным алгоритмом | 2 часа |
| 14. | Параллельный алгоритм умножения матрицы на вектор и его ускорение по сравнению с последовательным алгоритмом | 2 часа |
| 15. | Параллельный алгоритм умножения матрицы на матрицу и его ускорение по сравнению с последовательным алгоритмом | 2 часа |
| 16. | Параллельный алгоритм решения СЛАУ прямым методом Гаусса и его ускорение по сравнению с последовательным алгоритмом | 2 часа |
| 17. | Параллельный алгоритм решения СЛАУ итерационными методами Якоби, Гаусса - Зейделя и их ускорение по сравнению с последовательным алгоритмом | 2 часа |
| 18. | Специальные приемы параллельного программирования | 2 часа |
| Всего | 36 часов |
Планы семинарских занятий
| 1. | Установка и настройка операционной системы Linux (два варианта загрузки ОС: Linux, Windows98) | 2 часа |
| 2. | Установка и настройка MPI | 2 часа |
| 3. | Первая параллельная программа: обрамляющие функции (MPI_Init, MPI_Finalize), определение общего числа процессоров (MPI_Comm_Size), индивидуального номера процесса (MPI_Comm_Rank), вывод имен узлов кластера (MPI_Get_Processor_Name) | 2 часа |
| 4. | Передача данных с помощью блокирующих коммуникационных функций типа “Точка-Точка” (MPI_Send, MPI_Recv) | 2 часа |
| 5. | Другие виды передачи данных с помощью коммуникационных функций типа “Точка-Точка” (MPI_Ssend, MPI_Bsend, MPI_Rsend, MPI_Isend, MPI_Irecv) | 2 часа |
| 6. | Одновременная передача данных (MPI_Sendrecv) | 2 часа |
| 7. | Коллективные операции для синхронизации процессов (MPI_Barrier), для рассылки информации от одного процесса всем остальным процессам (MPI_Bcast), для сборки распределенного по процессам массива в один массив (MPI_Gather, MPI_Allgather), для распределения массива по процессорам (MPI_Scatter) | 2 часа |
| 8. | Глобальные вычислительные операции (MPI_Reduce, MPI_Allreduce, MPI_Reduce_scatter) | 2 часа |
| 9. | Создание производных типов данных с помощью конструкторов (MPI_Type_vector и др.) | 2 часа |
| 10. | Упаковка данных для пересылок (MPI_Pack) и распаковка (MPI_Unpack) | 2 часа |
| 11. | Установка пакета Scalapack для матричных параллельных вычислений.Тестирование коммуникационной среды кластера. Тестирование производительности кластера | 2 часа |
| 12. | Реализация параллельного алгоритма умножения матрицы на вектор в случае, когда все данные расположены на головном процессоре. Реализация параллельного алгоритма умножения матрицы на вектор в случае, когда матрица распределена построчно на все процессора, а вектор хранится на всех. Реализация параллельного алгоритма умножения матрицы на вектор в случае, когда матрица распределена по столбцам на все процессора, а вектор хранится на всех. Вычисление ускорения и эффективности параллельного алгоритма по сравнению с последовательным | 2 часа |
| 13. | Реализация параллельного алгоритма умножения матрицы на матрицу в случае, когда 1 матрица распределена построчно на все процессора, а другая по столбцам. Реализация параллельного алгоритма умножения матрицы на матрицу в случае, когда 1 матрица распределена по столбцам на все процессора, а другая построчно. Вычисление ускорения и эффективности параллельного алгоритма по сравнению с последовательным | 2 часа |
| 14. | Реализация параллельного алгоритма решения СЛАУ прямым методом Гаусса и вычисление его ускорения по сравнению с последовательным алгоритмом | 6 часов |
| 15. | Реализация параллельного алгоритма решения СЛАУ итерационными методами и вычисление их ускорения по сравнению с последовательным алгоритмом | 4 часа |
| Всего | 36 часов |
Семестровое задание выдается в середине курса каждому студенту индивидуально. Индивидуальность каждого задания обеспечивается различными алгоритмами, которые студентам необходимо распараллелить. Кроме распараллеливания алгоритма студентам необходимо провести полное исследование свойств параллельного алгоритма по следующей схеме:
1) написать последовательный алгоритм решения задачи;
2) вычислить кол-во операций на реализацию последовательного алгоритма
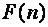 ,
где
,
где 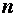 - размерность задачи;
- размерность задачи;
3)
определить время, затраченное на реализацию последовательного
алгоритма 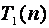 ;
;
4)
определить производительность компьютера на последовательном
алгоритме (![]() );
);
5) написать параллельный алгоритм решения задачи;
6) с помощью Jumpshot получить графическое представление всех используемых пересылок данных, определить время, затраченное на пересылку данных и вычислительные операции в зависимости от размерности решаемой задачи;
7) определить время, затраченное на реализацию параллельного алгоритма
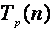 (р – количество процессоров);
(р – количество процессоров);
8)
определить производительность кластера на параллельном алгоритме (
 );
);
9)
вычислить ускорение параллельного алгоритма по сравнению с
последовательным 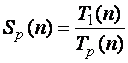 ;
;
10)вычислить эффективность параллельного алгоритма
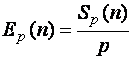 .
.
Литература
| 1. | Афанасьев К.Е., Стуколов С.В., Демидов А.В., Малышенко В.В. Многопроцессорные вычислительные системы и параллельное программирование (unesco.kemsu.ru) |
| 2. | Бахвалов Н.С. Численные методы. М.: Наука, 1975. |
| 3. | Березин И.С., Жидков Н.П. Методы вычислений. М.: Физматгиз, 1966. Т.1. |
| 4. | Воеводин В.В., Воеводин Вл.В. Параллельные вычисления С-П: БХВ-Петербург, 2002г. |
| 5. | Голуб Дж., Ван Лоун Ч. Матричные вычисления/ Пер. с англ. М.: Мир, 1999. 548 с. |
| 6. | Дацюк В.Н., Букатов А.А., Жегуло А.И. Методическое пособие по курсу “Многопроцессорные системы и параллельное программирование” / Ростов. госун-т. Ростов-на-Дону, 2000. Ч. I. 36 c. Ч. II. 65 c. |
| 7. | Корнеев В.В. Параллельные вычислительные системы. М: Нолидж, 1999. 320 с. |
| 8. | Кусимов С.Т. и др. Высокопроизводительные вычислительные ресурсы УГАТУ: состояние, перспективы развития и подготовка кадров // Теоретические и прикладные вопросы современных информационных технологий: Материалы конференции. Улан-Удэ: изд. ВСГТУ. 2001. С. 17-21. |
| 9. | Материалы информационно-аналитического центра НИВЦ МГУ – www.parallel.ru |
| 10. | Материалы ВЦ РАН - www.ccas.ru/paral |
| 11. | Ортега Дж. Введение в параллельные и векторные методы решения линейных систем/Пер. с англ. М.: Мир, 1991. 367 с. |
| 12. | Фортран 77 для ПЭВМ ЕС: Справ. изд./ З.С. Брич и др. М.: Финансы и статистика, 1991. 288с. |
| 13. | Шнитман В. Современные высокопроизводительные компьютеры.1996г. www.citforum.ru/hardware/svk/contents.shtml |
| 14. | MPI: Complete Reference www.netlib.org/utk/papers/mpi-book |
| 15. | Tutorial on MPI: The Message-Passing Interface William Gropp Mathematics and Computer Science Division Argonne National Laboratory Argonne, IL 60439 www-unix.mcs.anl.gov/mpi/tutorial |