Приведенные параллельные алгоритмы матрично-векторного произведения естественным образом обобщаются на задачу умножения матриц. Приведенные же ниже алгоритмы будут обсуждаться с точки зрения того, как хранились матрицы до операции произведения и после нее.
Для простоты возьмем квадратные матрицы
![]() и
и
![]() размерности
размерности
![]() .
.
Первый вариант параллельного алгоритма матричного умножения
будем строить, предполагая, что матрица
![]() распределена по процессорам слоистым образом по строкам, а
матрица
распределена по процессорам слоистым образом по строкам, а
матрица
![]() - целиком. В этом случае искомый результат можно получить,
выполнив параллельно на каждом процессоре
- целиком. В этом случае искомый результат можно получить,
выполнив параллельно на каждом процессоре
![]() скалярных произведений.
скалярных произведений.
Приведем алгоритм:
Шаг 1:
![]() на
на
![]()
Шаг 2:
![]() на
на
![]() (причем циклы по индексам расположены в следующей
последовательности
(причем циклы по индексам расположены в следующей
последовательности
![]()
Шаг 3:
![]()
Второй вариант параллельного алгоритма матричного умножения
будем строить, предполагая, что матрица
![]() распределена по процессорам слоистым образом по столбцам, а
матрица
распределена по процессорам слоистым образом по столбцам, а
матрица
![]() - целиком. В этом случае искомый результат можно получить,
выполнив параллельно на каждом процессоре умножение соответствующих столбцов
матрицы
- целиком. В этом случае искомый результат можно получить,
выполнив параллельно на каждом процессоре умножение соответствующих столбцов
матрицы
![]() на соответствующие элементы строк матрицы
на соответствующие элементы строк матрицы
![]() ,
затем необходимо осуществить частичное суммирование
получившихся произведений и на последнем шаге, переслав матрицы с частичными
суммами на один процессор, закончить суммирование. Алгоритм опустим ввиду его
громоздкости и очевидности.
,
затем необходимо осуществить частичное суммирование
получившихся произведений и на последнем шаге, переслав матрицы с частичными
суммами на один процессор, закончить суммирование. Алгоритм опустим ввиду его
громоздкости и очевидности.
Возможные способы хранения исходных матриц порождают другие
алгоритмы. Например, матрица
![]() распределена по процессорам слоистым образом по строкам, а
матрица
распределена по процессорам слоистым образом по строкам, а
матрица
![]() - целиком, или
- целиком, или
![]() распределена по процессорам слоистым образом по столбцам, а
распределена по процессорам слоистым образом по столбцам, а
![]() - целиком.
Алгоритмы при этом схожи с рассмотренными выше.
- целиком.
Алгоритмы при этом схожи с рассмотренными выше.
Возможно также построение алгоритмов, которые основаны на
блочном распределении матриц
![]() и
и
![]() по процессорам.
по процессорам.
Если разбиения обеих матриц на блоки согласованы, то
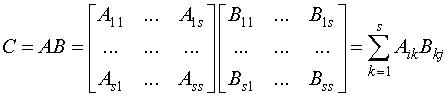 ,
,
где
![]() или
или
![]() - миноры соответствующих матриц. Это представление можно
реализовать разными алгоритмами. Пусть, например, число процессоров
- миноры соответствующих матриц. Это представление можно
реализовать разными алгоритмами. Пусть, например, число процессоров
![]() равно
равно
![]() (числу миноров матрицы
(числу миноров матрицы
![]() . При условии, что матрицы
. При условии, что матрицы
![]() и
и
![]() распределены соответствующим образом по процессорам, все
миноры матрицы
распределены соответствующим образом по процессорам, все
миноры матрицы
![]() можно вычислять одновременно.
можно вычислять одновременно.
На рис. 57 приведен текст Фортран-программы, реализующей
параллельный алгоритм умножения матрицы
![]() на матрицу
на матрицу
![]() в случае, когда матрица
в случае, когда матрица
![]() распределена построчно по процессорам, а
распределена построчно по процессорам, а
![]() - целиком.
- целиком.

Рис. 57. Пример распараллеливания алгоритма произведения матриц