Рассмотрим систему линейных алгебраических уравнений
с невырожденной матрицей
![]() размером
размером
![]() .
Наиболее известной
формой гауссова исключения является та, в которой система
(1) приводится к верхнетреугольному виду путем вычитания одних
уравнений, умноженных на подходящие числа, из других уравнений, полученная
треугольная система решается с помощью обратной подстановки. Математически все
это эквивалентно тому, что вначале строится разложение
.
Наиболее известной
формой гауссова исключения является та, в которой система
(1) приводится к верхнетреугольному виду путем вычитания одних
уравнений, умноженных на подходящие числа, из других уравнений, полученная
треугольная система решается с помощью обратной подстановки. Математически все
это эквивалентно тому, что вначале строится разложение
![]() ,
где L - нижнетреугольная матрица, с единицами на главной
диагонали, а U - верхнетреугольная матрица. Затем решаются треугольные
системы:
,
где L - нижнетреугольная матрица, с единицами на главной
диагонали, а U - верхнетреугольная матрица. Затем решаются треугольные
системы:
![]() .
(2)
.
(2)
Процесс их решения называется прямой и обратной подстановками. Рассмотрим сначала LU – разложение, занимающее большую часть времени всего процесса решения СЛАУ. Псевдокод разложения можно представить следующим образом:
|
Для k=1 до n-1 Для i=k+1 до n lik =aik/akk Для j=k+1 до n aij=aij-lik*akj
|
Для k=1 до n-1 Для s=k+1 до n lsk =ask/akk Для j=k+1 до n Для i=k+1 до n aij=aij - lik*akj |
|
|
Строчно-ориентированная схема LU – разложения |
Столбцово-ориентированная схема LU – разложения |
|
Предположим вначале, что мы располагаем вычислительной системой с локальной памятью и числом процессоров p=n. Пусть i-я строка матрицы A хранится в процессоре i. Тогда один из возможных вариантов организации LU-разложения заключается в следующем: на первом шаге первая строка рассылается всем процессорам, после чего вычисления
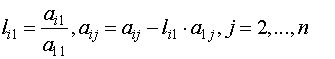
могут выполняться параллельно процессорами p2, ...,pn. На втором шаге вторая строка приведенной матрицы рассылается из процессора p2 процессорам p3, ..., pn , a затем проводятся параллельные вычисления и т. д. Алгоритм первых четырех шагов приведен ниже.
Шаг 1:
Шаг 2:
![]() на
на
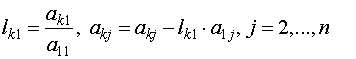
Шаг 3:
![]()
Шаг 4:
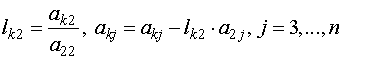 на
на
![]()
Отметим два главных недостатка этого подхода: значительный объем обмена данными между процессорами и уменьшение числа активных процессоров на 1 через каждый шаг.
Альтернативой хранению по строкам является вариант, в котором i-й столбец матрицы А хранится в процессоре i. В этом случае на первом шаге все множители li1 вычисляются в процессоре 1 и рассылаются остальным процессорам. Затем процессорами 2,…,n параллельно производятся модификации
![]() .
.
Вычислив множители 1i1, процессор 1 прекращает работу; вообще, с каждым шагом число простаивающих процессоров увеличивается на единицу. Возникает та же, что и в строчно-ориентированном алгоритме, проблема балансировки нагрузки.
В более реалистической ситуации, когда
![]() ,
проблема балансировки нагрузки в известной степени
смягчается. Предположим, что
,
проблема балансировки нагрузки в известной степени
смягчается. Предположим, что
![]() и применяется хранение по строкам. Поместим первые k
строк матрицы А в память процессора 1, следующие k строк в память
процессора 2 и т. д. Этот способ хранения назовем блочной схемой. Снова
первая строка рассылается из процессора 1 остальным процессорам, а затем
выполняются необходимые вычисления, однако теперь это делается блоками по k
наборов операций в каждом процессоре. Как и прежде, в ходе приведения все
большее число процессоров становятся бездействующими, однако отношение общего
времени вычислений к времени обменов и времени простоев является возрастающей
функцией от k.
и применяется хранение по строкам. Поместим первые k
строк матрицы А в память процессора 1, следующие k строк в память
процессора 2 и т. д. Этот способ хранения назовем блочной схемой. Снова
первая строка рассылается из процессора 1 остальным процессорам, а затем
выполняются необходимые вычисления, однако теперь это делается блоками по k
наборов операций в каждом процессоре. Как и прежде, в ходе приведения все
большее число процессоров становятся бездействующими, однако отношение общего
времени вычислений к времени обменов и времени простоев является возрастающей
функцией от k.
Более привлекательна
схема хранения, в которой строки, распределенные в разные процессоры, как бы
прослаивают друг друга. Будем по-прежнему считать, что
![]() ,
и пусть строки 1, p+1, 2р+1,... хранятся в процессоре
1, строки 2, p+2, 2p+2, ... - в процессоре 2 и т. д.
Такой способ хранения мы будем называть циклической слоистой схемой.
Проблема простоя процессоров для этой схемы теряет остроту; например,
процессор 1 будет работать почти до самого конца приведения, а именно до тех
пор, пока не закончится обработка строки (k-1)р+1. Разумеется, некоторая
неравномерность загрузки процессоров сохранится. Так, после первого шага строка
1 станет не нужна, и на следующем шаге процессору 1 придется обрабатывать на
одну строчку меньше, чем остальным процессорам. Неравномерность сходного типа
возникает и в том вполне вероятном случае, когда n не кратно числу
процессоров.
,
и пусть строки 1, p+1, 2р+1,... хранятся в процессоре
1, строки 2, p+2, 2p+2, ... - в процессоре 2 и т. д.
Такой способ хранения мы будем называть циклической слоистой схемой.
Проблема простоя процессоров для этой схемы теряет остроту; например,
процессор 1 будет работать почти до самого конца приведения, а именно до тех
пор, пока не закончится обработка строки (k-1)р+1. Разумеется, некоторая
неравномерность загрузки процессоров сохранится. Так, после первого шага строка
1 станет не нужна, и на следующем шаге процессору 1 придется обрабатывать на
одну строчку меньше, чем остальным процессорам. Неравномерность сходного типа
возникает и в том вполне вероятном случае, когда n не кратно числу
процессоров.
Тот же принцип прослаивания можно использовать при хранении по столбцам: теперь столбцы 1, р+1, …, (k-1)p+1 закреплены за процессором 1, столбцы 2, р+2,…, (k-1)p+2 - за процессором 2 и т. д. Снова все процессоры (при небольшом дисбалансе нагрузки) будут работать почти до конца приведения.
Обсудим теперь более подробно LU- разложение с использованием циклической слоистой схемы хранения. На первом шаге аннулируются элементы первого столбца. Если процесс ведется обычным последовательным образом, то вычисляются множители li1, модифицируются соответствующие строки, а затем начинается второй шаг. В начале этого шага процессор, хранящий вторую строку, должен переслать ее остальным процессорам. Следовательно, возникает задержка на время этой пересылки. Очевидным выходом из положения является немедленная рассылка процессором 2 модифицированной второй строки, как только эта строка приняла окончательный вид. Такую стратегию мы назовем опережающей рассылкой. Если можно совместить вычисления и обмены, то все процессоры будут заняты модификациями первого шага, пока идет рассылка. То же самое будет происходить и на других шагах: на k-м шаге (k+1)-я строка рассылается сразу после того, как окончится ее модификация. Насколько выгодна эта стратегия для конкретной вычислительной системы, зависит от топологии ее межпроцессорных связей.
После выполнения LU-разложения нужно решать треугольные системы уравнений. Мы рассмотрим только верхнетреугольную систему Ux=с. Основными методами снова будут обсуждавшиеся ранее столбцовый алгоритм и алгоритм скалярных произведений. Псевдокод решения верхнетреугольной системы уравнений можно представить следующим образом:
|
Для i=n с шагом –1 до 1 Для j=i+1 до n ci=ci-xjuij xj=cj/ujj |
Для j=n с шагом –1 до 1 хj=cj/ujj Для i=1 до j–1 ci=ci-xjuij |
|
Строчно-ориентированный алгоритм |
Столбцово-ориентированный алгоритм |
Если считать, что
матрица U является результатом ранее выполненного LU-разложения, то способ
распределения (хранения) матрицы
![]() уже предопределен схемой хранения, использовавшейся при
разложении. Например, если использовалась строчная циклическая слоистая схема
распределения при разложении, то точно таким же образом построчно будет
распределена и матрица U. Предположим, что и правая часть системы распределена
послойно по процессорам. Тогда одна из возможных реализаций
строчно-ориентированного алгоритма выглядит так:
уже предопределен схемой хранения, использовавшейся при
разложении. Например, если использовалась строчная циклическая слоистая схема
распределения при разложении, то точно таким же образом построчно будет
распределена и матрица U. Предположим, что и правая часть системы распределена
послойно по процессорам. Тогда одна из возможных реализаций
строчно-ориентированного алгоритма выглядит так:
Шаг 1:
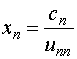 на
на
![]()
Шаг 2:
![]()
Шаг 3:
![]() на
на
![]()
Шаг 4:
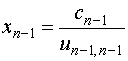 на
на
![]()
Шаг 5:
![]() и
и
![]()
Шаг 6:
![]() на
на
![]()
На первом шаге
![]() и
и
![]() хранятся на последнем процессоре, где вычисляется значение
хранятся на последнем процессоре, где вычисляется значение
![]() ,
на втором шаге оно пересылается на все процессоры, на
третьем шаге все процессоры пересчитывают хранящиеся на нем компоненты правой
части, затем в процессоре, содержащем
,
на втором шаге оно пересылается на все процессоры, на
третьем шаге все процессоры пересчитывают хранящиеся на нем компоненты правой
части, затем в процессоре, содержащем
![]() -ю строку, вычисляется
-ю строку, вычисляется
![]() и т.д.
В результате повторения этого процесса вычисляется
и т.д.
В результате повторения этого процесса вычисляется
![]() ,
,
![]() ...
...
![]() .
Для реализации как строчно-, так и столбцово-ориентированных
алгоритмов присущи следующие недостатки: на каждом шаге для вычисления
последующего элемента вектора неизвестных
необходима пересылка данных, на заключительных шагах все большее число
процессоров простаивает.
.
Для реализации как строчно-, так и столбцово-ориентированных
алгоритмов присущи следующие недостатки: на каждом шаге для вычисления
последующего элемента вектора неизвестных
необходима пересылка данных, на заключительных шагах все большее число
процессоров простаивает.
Если учесть, что на
реализацию LU-разложения приходится
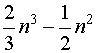 арифметических операций, а на решение треугольной системы -
арифметических операций, а на решение треугольной системы -
![]() операций и при недостаточно высокой скорости передачи данных,
то алгоритм решения верхнетреугольной системы уравнений целесообразнее не
распараллеливать.
операций и при недостаточно высокой скорости передачи данных,
то алгоритм решения верхнетреугольной системы уравнений целесообразнее не
распараллеливать.
В таблице 14 приведены временные затраты на LU-разложение и решение верхнетреугольной системы уравнений. Из данной таблицы видно, что решение верхнетреугольной системы уравнений занимает много меньше 1% от общего времени решения СЛАУ и его алгоритм вполне можно не распараллеливать.
Таблица 14
|
Размерность ( |
Время на LU-разложение (сек.) |
Время на решение верхнетреугольной системы уравнений (сек.) |
|
1000 |
62,54 |
0,21 |
|
2000 |
494,95 |
0,47 |
На рис. 58 приводится листинг параллельной программы для решения СЛАУ столбцово-ориентированным методом Гаусса с выбором ведущего элемента.

Рис. 58. Листинг программы, реализующей параллельный алгоритм решения СЛАУ методом Гаусса