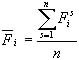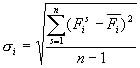|
|
Тема 7.
Статистическая обработка данных
>>Алгоритм создания тезауруса
|
|
На первом этапе в пределах исследуемой области знаний определяются
тематические подобласти, которые в дальнейшем станут основой
тезауруса.
Допустим, в результате проведенного анализа в пределах некоторого подъязыка выделено n тем:
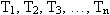 . .
|
|
На втором этапе подбирается количество лингвистических единиц, которые войдут в темы
, и тексты,
содержащие эти темы. Количество единиц в темах должно соответствовать весу темы в реальных
текстах данного подъязыка, отбор текстов должен проводиться из разных источников с
соблюдением правил, обеспечивающих случайность выборки.
|
|
Пусть исследуемая длина текста N состоит из n отдельных частей (по числу тем),
в каждой из которых содержится по 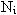 словоупотреблений
(i = 1, 2, … n):
словоупотреблений
(i = 1, 2, … n):
|
|
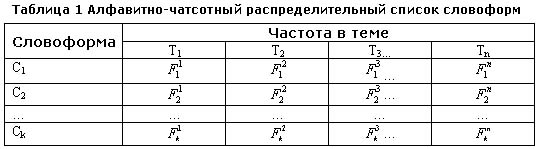
На третьем этапе анализа строится алфавитно-частотный распределительный список
всех словоформ подъязыка в следующем виде (таблица 1):
|
|
Полученный частотный словарь служит основой для выделения ключевых слов.
Если в понятие "ключевое слово" вкладывается широкое содержание, т.е. ключевым
словом считается любая лингвистическая единица, имеющая специфическое распределение
в определенном тексте (это может быть и предлог, и определенная форма глагола, и др.),
то дальнейшему анализу подвергается весь частотный список.
Если же под "ключевым словом" понимать общепринятое содержание этого понятия,
то для дальнейшего анализа отбираются лишь существительные, прилагательные и некоторые глаголы.
|
|
Дальнейший анализ:
Для каждой исследуемой словоформы 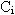 частотного списка вычисляется коэффициент вариации
частотного списка вычисляется коэффициент вариации
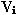 : :
где 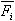 -
средняя арифметическая частот -
средняя арифметическая частот 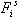 (s = 1, 2, …, n) словоформы
во всех темах: (s = 1, 2, …, n) словоформы
во всех темах:
 - среднее квадратическое отклонение: - среднее квадратическое отклонение:
Коэффициент вариации показывает, насколько частоты слова (словоформы)
в различных темах отклоняются от некоторой средней частоты , и может служить показателем однородности исследуемого материала по отношению к данному слову
.
- Если величина
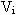 для конкретного слова меньше некоторого критического значения
для конкретного слова меньше некоторого критического значения
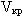 , то все темы для анализируемого слова являются однородными и такое слово нельзя считать ключевым. , то все темы для анализируемого слова являются однородными и такое слово нельзя считать ключевым.
- Если же
> , то материал считается неоднородным по отношению к слову
, т.е. какая-то одна тема (или несколько) из тем особым образом тяготеет к исследуемому слову
. В таком случае слову
считается ключевым в той теме, в которой это слово имеет наибольшую частоту
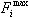 . .
- Может оказаться, что при >
слово в двух темах имеет одинаковую максимальную частоту. Тогда слово будет считаться ключевым в обеих темах.
- Возможен случай, когда >
частоты слова в некоторых Т темах достаточно близки друг к другу. Тогда подсчитывается вероятность, с которой слово можно считать ключевым в каждой из тем.
|
|
|
Заключительный этап. Выделенные при
таком подходе списки слов являются
лишь потенциально ключевыми. При тщательном их просмотре с учетом значений
и
дополнительного исследования вероятности, с которой слово может считаться ключевым
в каждой теме (теорема Байеса) специалист отберет те слова, которые войдут в
соответствующий тезаурус.
|
|