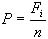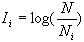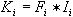|
|
Тема 7.
Статистическая обработка данных
>>Анализ текста
|
|
В связи с бурным развитием массовой и деловой коммуникации, ростом информационных
потоков, интенсивным накоплением информации, предназначенной для систематизации,
хранения и использования актуальной становится задача извлечения информации
(информационного поиска) и ее анализа. Компьютерный анализ текстов в настоящее
время начинает приобретать самостоятельное значение в проблематике гуманитарной
информатики. Наиболее разработанным направлением является использование статистических
методов для обработки текста, например, построение частотных словарей, конкордансов
(словарей словосочетаний) и т.п. Анализ может вестись на разных уровнях - от грамматических
форм (характерно для стилометрики) до смысловых категорий, обнаруживаемых в тексте
(контент-анализ). Цель анализа - выявить некоторые закономерности, характеризующие
текст, и сделать выводы, например, об авторстве текста или политических пристрастиях
автора. Известны различные методы выбора ключевых слов: статистические, выбор с помощью
анкет или кодограмм, выбор по совпадению данного слова со словами некоторого положительного
словаря и ряд других. Определение ключевых слов является основой для создания тезаурусов,
используемых в процессах автоматического поиска информации, автоматического аннотирования,
реферирования и перевода. Статистические методы выделения специфичной лексики основываются
на анализе частоты употребления того или иного слова в определенной совокупности текстов.
Пусть имеется текст T, следует взять любое слово
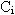 и посчитать, сколько раз оно встречается
в тексте - эта величина называется частотой вхождения и посчитать, сколько раз оно встречается
в тексте - эта величина называется частотой вхождения
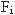 (употребления) слова
.
Вероятность встретить выбранное случайным образом слово равна отношению частоты
вхождения слова к общему числу слов n в тексте: (употребления) слова
.
Вероятность встретить выбранное случайным образом слово равна отношению частоты
вхождения слова к общему числу слов n в тексте:
|
|
Некоторые слова будут иметь одинаковую частоту, то есть входить в текст равное
количество раз. Следует сгруппировать слова, имеющие одинаковую частоту вхождения
и взять только одно значение из каждой группы. Расположить частоты в порядке убывания
и пронумеровать их. Порядковый номер частоты называется
рангом частоты. Наиболее часто
встречающиеся слова будут иметь ранг 1, следующие за ними - 2 и т.д.
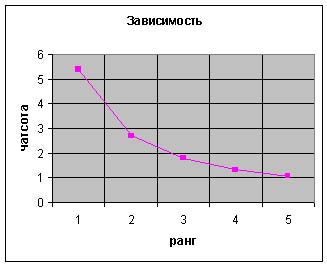
Исследования показывают, что наиболее значимые слова лежат в средней части графика
зависимости ранга от частоты. Слова, которые попадаются слишком часто, в основном
оказываются предлогами, местоимениями, в английском языке - артиклями и т.п. Редко
встречающиеся слова тоже, в большинстве случаев, не имеют решающего смыслового значения.
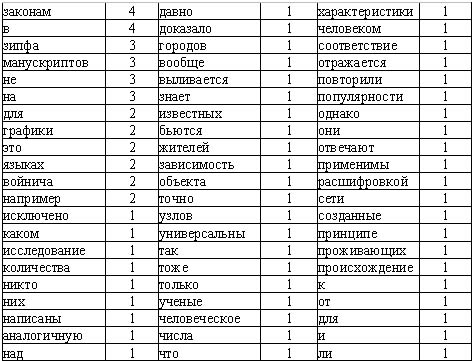
Например, провести анализ следующего текста, построить график зависимости ранга и частоты,
выделить зону значимых слов:
|
|
таблица слов текста с частотой их вхождения, слова с частотой 2 и 3 наиболее точно отражают смысл абзаца:
|
|
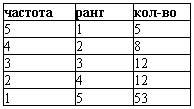
таблица ранжирования:
|
|
график зависимости частота-ранг:
|
|
зона значимых слов: слова с рангом 2, 3 и частотой 3, 2 соответственно.
|
|
Анализ выделенной области значимых слов. Не все слова, которые попали в нее, отражают смысл текста. Смысл абзаца очень точно выражают слова: зипфа, манускриптов, войнича, законам. Однако в область попали и слова: не, для, это. Эти слова являются "шумом", который затрудняет правильный выбор. "Шум" можно уменьшить путем предварительного исключения из исследуемого текста некоторых слов. Для этого создается словарь ненужных слов - стоп-словарь. Есть и другие способы повысить точность оценки значимости терминов.
Был рассмотрен отдельно взятый документ, но при выделении ключевых слов исследуется совокупность текстов. Чтобы избавится от лишних слов, и поднять рейтинг значимых слов, часто используется инверсная частота термина i. Значение этого параметра тем меньше, чем чаще слово встречается в документах. Вычисляется инверсная частота
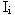 по следующей формуле: по следующей формуле:
где N - общее количество документов, 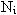 - количество документов с термином i. - количество документов с термином i.
Далее каждому термину присваивается весовой коэффициент, отражающий его значимость.
Весовой коэффициент 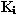 термина
в документе
термина
в документе
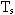 равен произведению частоты термина на инверсную частоту
данного термина. равен произведению частоты термина на инверсную частоту
данного термина.
В примере термин "не" получит нулевой или близкий к нулю весовой коэффициент, поскольку практически во всех текстах попадается это слово. Термин "зипфа" - напротив, приобретет высокий вес.
Современные способы индексирования не ограничиваются анализом перечисленных параметров текста. Поисковая машина может строить весовые коэффициенты с учетом местоположения термина внутри документа, взаимного расположения терминов, частей речи, морфологических особенностей и т.п.
В качестве терминов могут выступать не только отдельные слова, но и словосочетания. Без этих законов сегодня не обходится ни одна система автоматического поиска информации.
|
|